模型选择,请自行下载并准备好以下两个模型
1、Qwen/Qwen3.6-27B-FP8,作用:用来给下方的模型开启MTP
2、sakamakismile/Huihui-Qwen3.6-27B-abliterated-NVFP4
docker镜像
docker pull scitrera/dgx-spark-sglang:0.5.12
给镜像打补丁
mkdir docker-build
cd docker-build
输入nano Dockerfile,在其中填写以下内容
# 基于你提供的基础镜像
FROM scitrera/dgx-spark-sglang:0.5.12
# 切换到 root 用户(确保有安装权限)
USER root
# 安装你需要的所有 Python 包
RUN pip install --no-cache-dir \
cuda-tile \
tabulate \
nvidia-cudnn-cu12 \
nvidia-cudnn-frontend
# 容器启动命令(继承原镜像)
CMD ["/bin/bash"]
保存退出后,执行以下命令打包新镜像,请确保有科学上网的能力
docker build -t dgx-spark-sglang-nvfp4:latest .
完成后,输入docker images 查看镜像列表

运行模型,可以将下方代码保存到一个脚本中,方便后续调用
docker run -d --gpus all \
--privileged \
--restart unless-stopped \
--network host \
-v /data/models:/models \
--name sglang-Qwen3.6-27B-NVFP4 \
--ipc=host \
dgx-spark-sglang-nvfp4:latest \
sglang serve --sleep-on-idle \
--model-path /models/Huihui-Qwen3.6-27B-abliterated-NVFP4 \
--served-model-name "Qwen3.6-27B" \
--api-key "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" \
--reasoning-parser qwen3 \
--tool-call-parser qwen3_coder \
--speculative-algorithm EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--speculative-draft-model-path /models/Qwen3.6-27B-FP8/ \ ##官方模型此时用来作为MTP模型使用
--mamba-scheduler-strategy extra_buffer \
--context-length 262144 \
--trust-remote-code \
--host 0.0.0.0 \
--port 30000 \
--dtype auto \
--max-running-requests 4 \
--prefill-max-requests 4 \
--mem-fraction-static 0.4 \
--mamba-full-memory-ratio 0.1 \
--cuda-graph-max-bs 8 \
--radix-eviction-policy slru \
--schedule-policy lpm
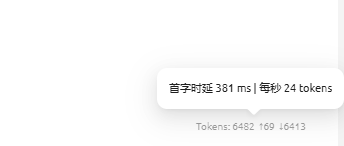
实测速度,最快可达到每秒27 tokens,图中没截到最快的
4 个帖子 - 2 位参与者
来源: LinuxDo 最新话题查看原文