今天在用Grok搜有意思的内容的时候,偶然发现 Supertonic这个开源项目,一个超快速、本地运行的多语言文本转语音(TTS)系统(但是不支持中文,中文的话可以找 Mimo-TTS系列模型)。
核心特点:
-
完全本地推理 — 基于 ONNX Runtime,无需云端、无 API 调用、无隐私顾虑
-
极低延迟 — 可在边缘设备上实时合成语音
-
支持31 种语言 — 包括英文、日文、韩文等
-
99M 参数 — 体积小,冷启动快
然后就引起了我的好奇心,平时我们在和Gemini,
豆包这些AI语音交流的时候,中间发生了什么?
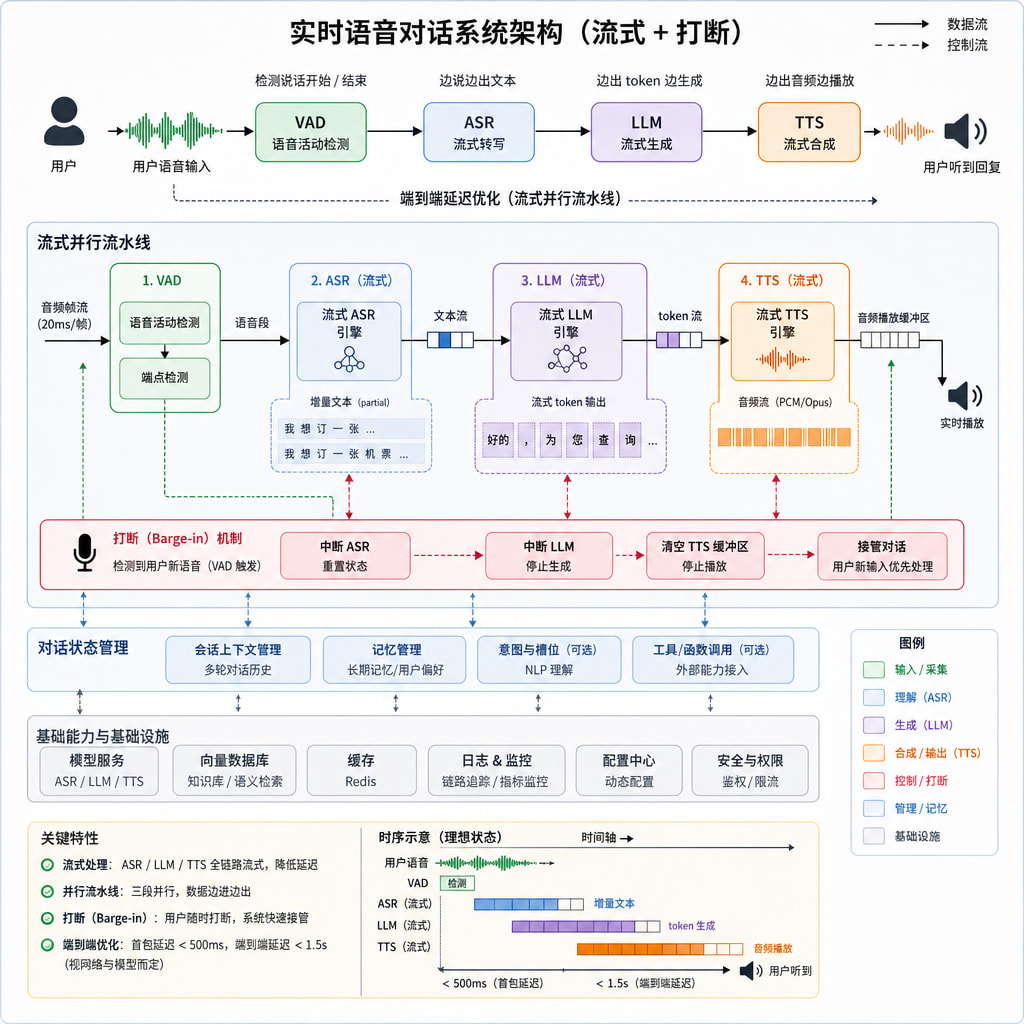
最新的技术方案还有端到端语音模型(如 GPT-4o realtime、Gemini Live),跳过中间文本环节,直接 spech-to-speech,延迟更低、能保留语气情感但是部署成本高。
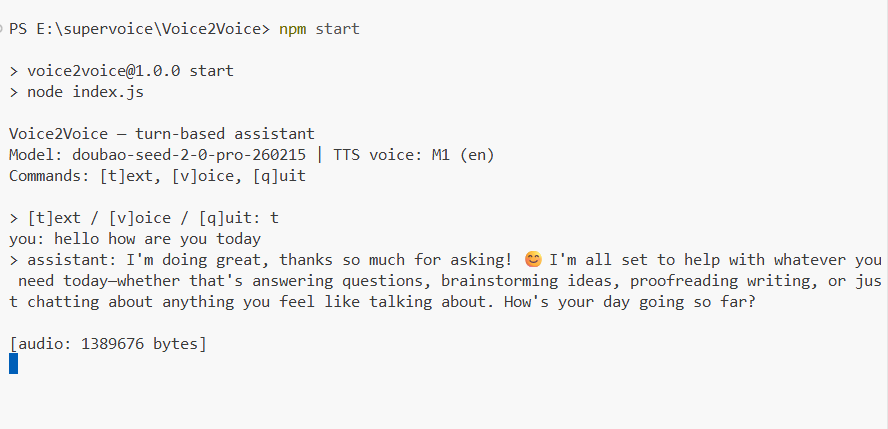
所以让Codex手搓了一个Voice/Text to Voice的一个MVP项目。
具体实现:用户(Win + H)语音转文字------>LLM的输入(支持/v1/chat/completions协议)------>LLM输出文本------>Supersonic输出语音。当然其中应该涉及到延迟, 打断 ,容错,信息丢失这些内容。今天一天暂时考虑不到这么多。
具体的成果就是可以在端侧,这里以Windows为例,实现简单的人与AI的语音对话。
1 个帖子 - 1 位参与者
来源: LinuxDo 最新话题查看原文