最近看到站内有不少朋友在分享并推崇这个大模型榜单,我来批判下,欢迎各位理性交流。
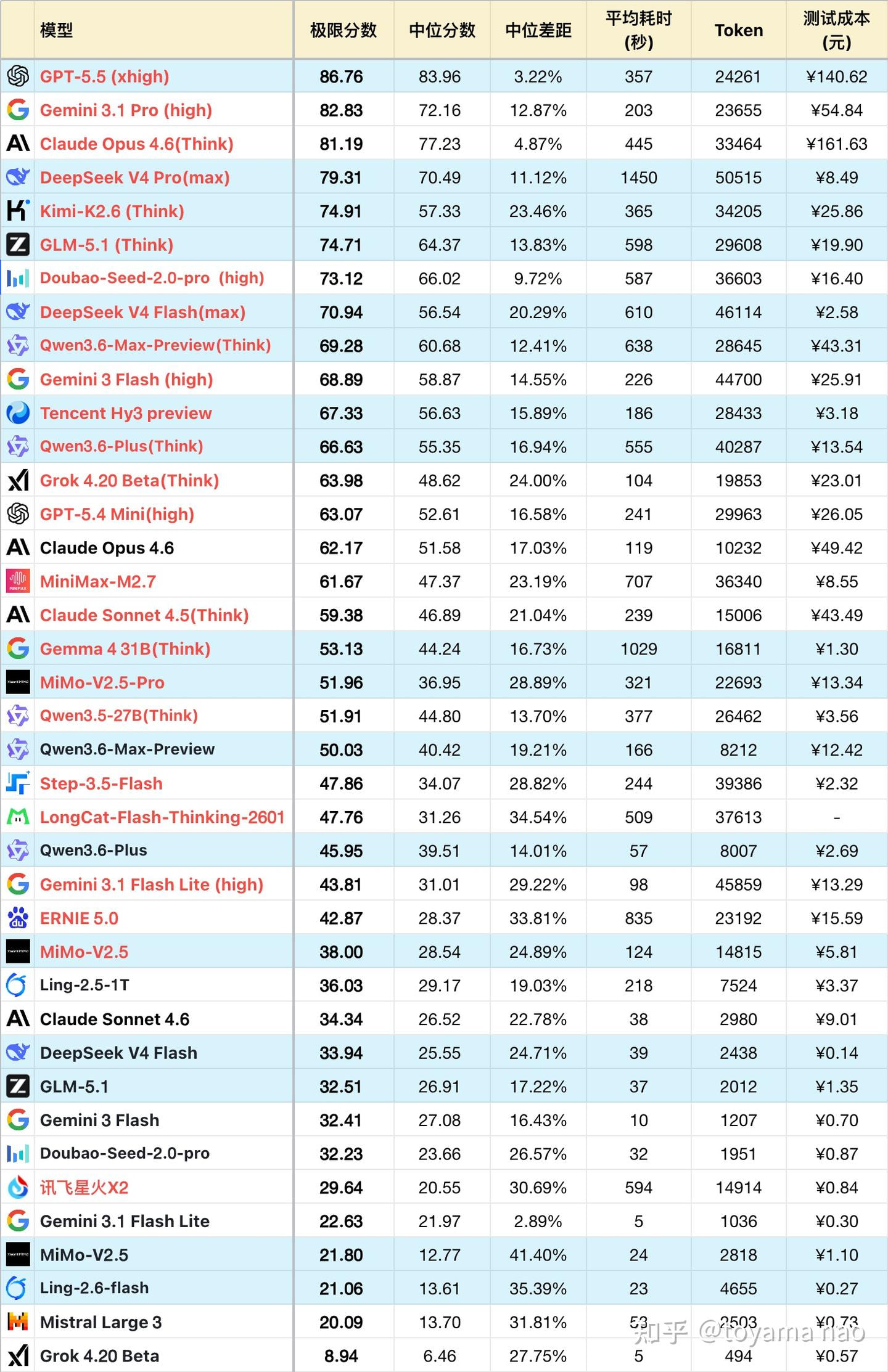
先回顾下这个榜单的基本情况:
性质 :个人性质评测,使用滚动更新的私有题库进行长期跟踪。
侧重点 :主要测试大模型在逻辑、数学、编程及人类直觉等方面的表现。由于不是全方位测试,主要提供一个观察大模型进化趋势的侧面视角。
体量 :题库数量在 60 道左右。
我的批判:
1. 题库样本量过小
相比于目前主流的 Humanity’s Last Exam (HLE) 等动辄 2100 道题的大型 Benchmark,60 道的题量在评估全面性和稳定性上存在明显差距。
2. 测能力变成了“掷硬币”——离谱的得分方差
在仅有 60 道题的盘子里,模型答题甚至会出现 30% 到 40% 的巨大震荡。这意味着模型做这套题的表现,很大程度上等同于“抛硬币盲猜”——运气好蒙对几题,或运气差错失几题,分数就会产生剧烈跳水。用这种极高方差的数据来排榜,很难真正证明“谁比谁聪明”,反而暴露了题库量太少、提示词可能存在诱导性,导致测试结果充满了极大的偶然性。
3. 开启 Think(思考)参数前后反差过于离谱
-
Grok 4.20 Beta (Think) :靠着思考模式狂砍 63.98 分,高居前列;但你往下看,它的基础原版 Grok 4.20 Beta 居然只有惊人的 8.94 分(全榜倒数第一!)。
-
Gemini 3 Flash (High) :得分 68.89 ,而原版 Gemini 3 Flash 仅为 32.41 分。
思考模式固然有加成,但在同一榜单中出现如此极端的分差,其评分机制的合理性有待商榷。
4. 排名与主流榜单存在较大出入
在 HLE 等当前尚未被“刷爆”的榜单上,Mimo v2.5 Pro 的表现远超 Qwen3.6 27B;但在该榜单中,二者成绩却相差无几。这种“千亿大模型(1T)与 27B 模型打平”的反差感,不可否认给榜单带来了流量,但也确实有悖于主流共识。
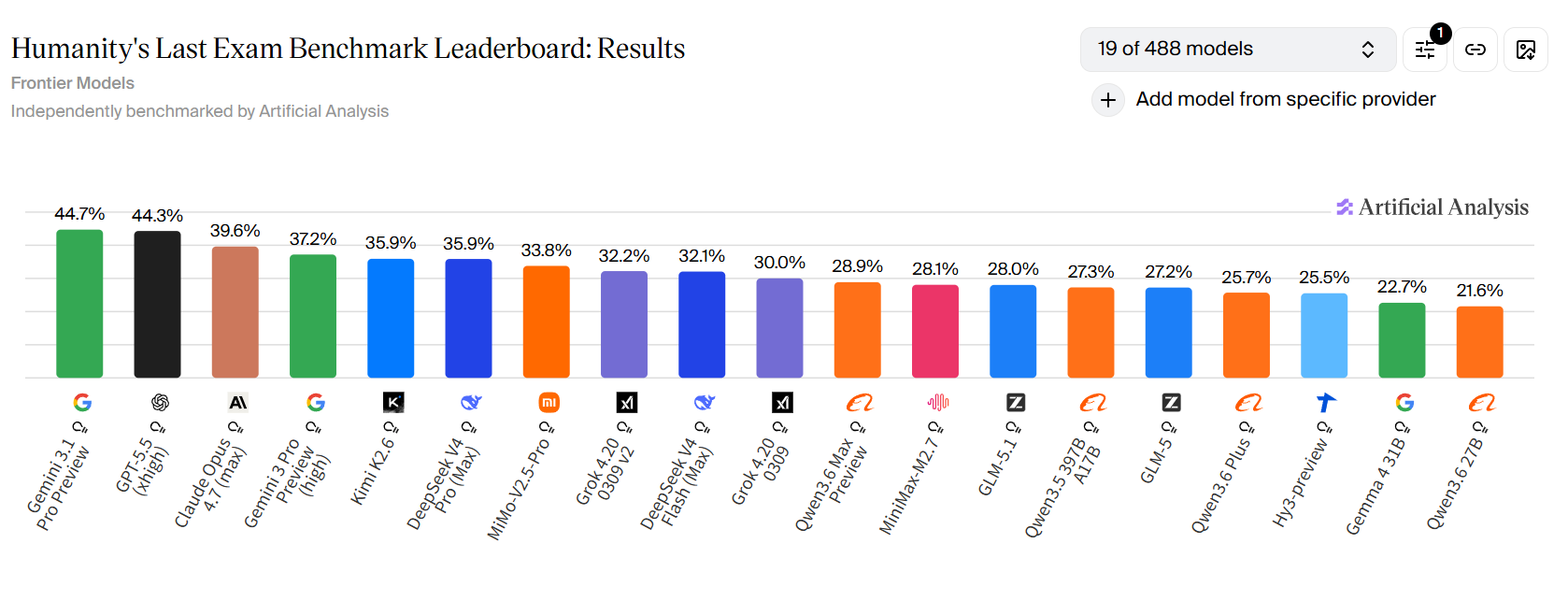
5. 作为主打“逻辑”的榜单,缺乏区分度
在题目设置上合理性欠佳,没有拉开区分度。表面上看,DeepSeek v4 Pro 和前三名分数咬得很紧,但事实上,在更多严谨的主流 Benchmark 上,它们之间的差距依然十分显著。
下面这道题,去年11月的gemini3.0pro可以解答,目前还没有一个国产模型可以正确回答,从这种问题可以看出来,很多所谓的逻辑题,都是有一定的逻辑陷阱,这里的陷阱就是形状是可以用手感知的。回答结果29的模型都没有注意到这一点,反而在用常规逻辑解答。
在一个黑色的袋子里放有三种口味的糖果,每种糖果有两种不同的形状(圆形和五角星形,不同的形状靠手感可以分辨)。现已知不同口味的糖和不同形状的数量统计如下表。参赛者需要在活动前决定摸出的糖果数目,那么,最少取出多少个糖果才能保证手中同时拥有不同形状的苹果味和桃子味的糖?(同时手中有圆形苹果味匹配五角星桃子味糖果,或者有圆形桃子味匹配五角星苹果味糖果都满足要求) 苹果味 桃子味 西瓜味 圆形 7 9 8 五角星形 7 6 4
6. 模型的思考深度及细节瑕疵
观察发现,排名靠后的模型平均输出 Token 通常很短。对于逻辑题而言,主流模型往往需要较长的思维链(CoT)来支撑。这里顺便吐槽下 DeepSeek 的老问题:思维链中的无效信息依然偏多。
另外榜单还有一些小瑕疵,比如榜上出现了两个 Mimo v2.5;还有 Gemma4 31B 的推理速度极慢,与直觉严重不符。
总结:
当然,个人制作榜单并坚持长期更新实属不易,非常感谢原作者的用心分享和付出。但综合以上几点,还是希望大家在评估 LLM 能力时能多方参考,不要单纯把这类榜单奉为圭臬来进行严谨的排名对比。
4 个帖子 - 3 位参与者