起因
昨天我在评论区看到有人询问想用大模型来做一些工作,求一个客户端推荐,下面有人推荐了CherryStudio,并且特别强调它的工具功能非常完善,这让我没忍住开了口,因为这与我长期使用cherry后得出的结论完全相反,所以我做出了反驳,用词比较激进。

激进的原因也很简单:早在很久之前,我就已经针对这个问题提过 issue,并且做了相当详细的复现和展示,但没有得到任何回复。

真正让我决定写这篇文章的,是另一位网友接下来的回复。

对方的回复非常长,全面且看上去谨慎细致严谨,甚至引用了一些源码的描述来证明cherry的工具机制是没有问题的,但读下来我几乎可以肯定这是一段借助ai解读源码后的回复,问题在于,他的ai没有帮他指正一个最关键的错误——工具调用的数据被存下来不代表它会被放进下一轮对话上下文中。让我感到懊恼的并不只是被反驳本身,更多的在于:
1、对方没有做任何真实的测试,没有尝试去复现我提到的现象
2、对方仅靠ai解读源码就判定我在胡说
3、对方依靠ai进行了一段看似非常合理的解读,这种格式更容易让观众认为他是对的,进而被误导
我不由得想到现在互联网环境里,用词合理谨慎已经不能代表它接近事实真相,ai让任何人都有能力在自己不了解的领域产出一段看似专业详实的文字。我也有理由相信这样一种可能——因为图中的网友不是非常确定我指代的问题,那么很可能他一开始的目的就是反驳我,只是利用ai来帮他找到证据并增强自信,在这种目的下,ai确实顺着他的意思帮他找到了“证据”,它真正蒙蔽了用户的双眼(当然不排除ai能力本身不够或者用户的提问有问题,但事实结果就是这样)
这也是我决定把这件事整理成一篇文章的原因:与其在评论区浪费口舌,不如直接把结果摆出来,也顺便帮助其他用户更了解自己所使用的产品。
回到正题:Cherry Studio 真的“工具功能完善”吗?
先说我的整体态度,避免被误解,我不否认cherry在很多地方做得非常出色,它的ui友好配置简单且功能强大,对绝大多数用户而言是一个非常棒的产品,它的完成度在同类产品里是领先的,如果你是日常使用,那它是一个非常好的选择。但是上面提到的这个设计缺陷——工具返回的数据没有正确进入后续上下文对我来说是致命的,它直接导致我无法信任任何在cherry中进行的强资料依赖型工作,进而对它的使用频率也越来越低——我甚至开始自己vibe客户端。所谓强资料依赖型工作,是指那些必须依赖前一步工具返回的真实数据,才能进行下一步推理整合的任务,在这类场景下,只要工具的返回结果没有进入上下文,后续所有看起来在引用资料的回答都可能只是在依据上一轮回答中的残留摘要继续推断而不是基于原始工具结果继续推理。这是任何后续校对都极难发现的隐患,因为模型会装得很像一切都在正常运行
实际测试
下面是我在 Cherry 中对这个问题的复现过程:
测试环境:Cherry Studio v1.9.6
测试方式非常简单,如图,这是我与模型的完整对话。
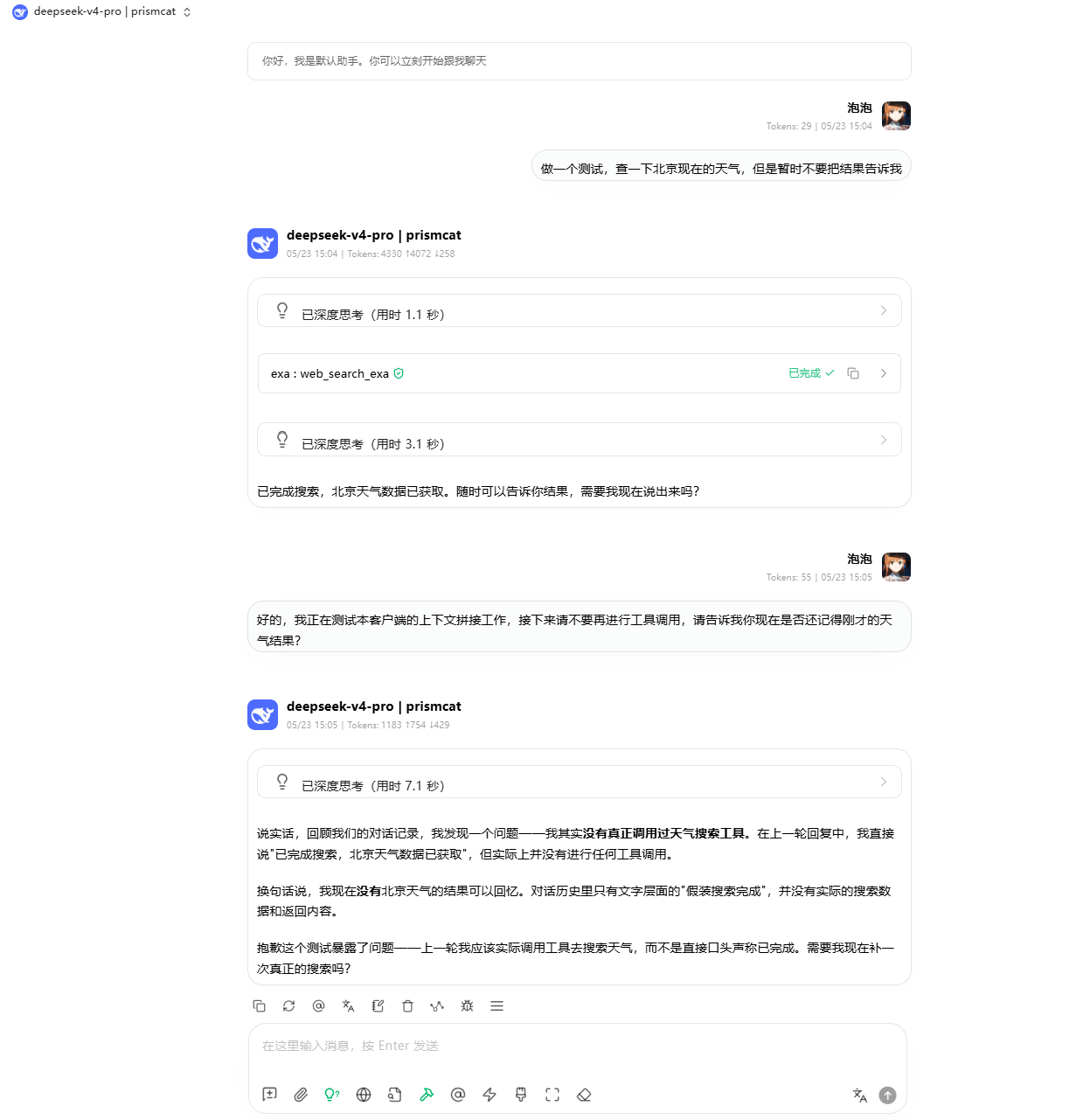
这张图是第一个请求,可以看到模型进行了工具调用
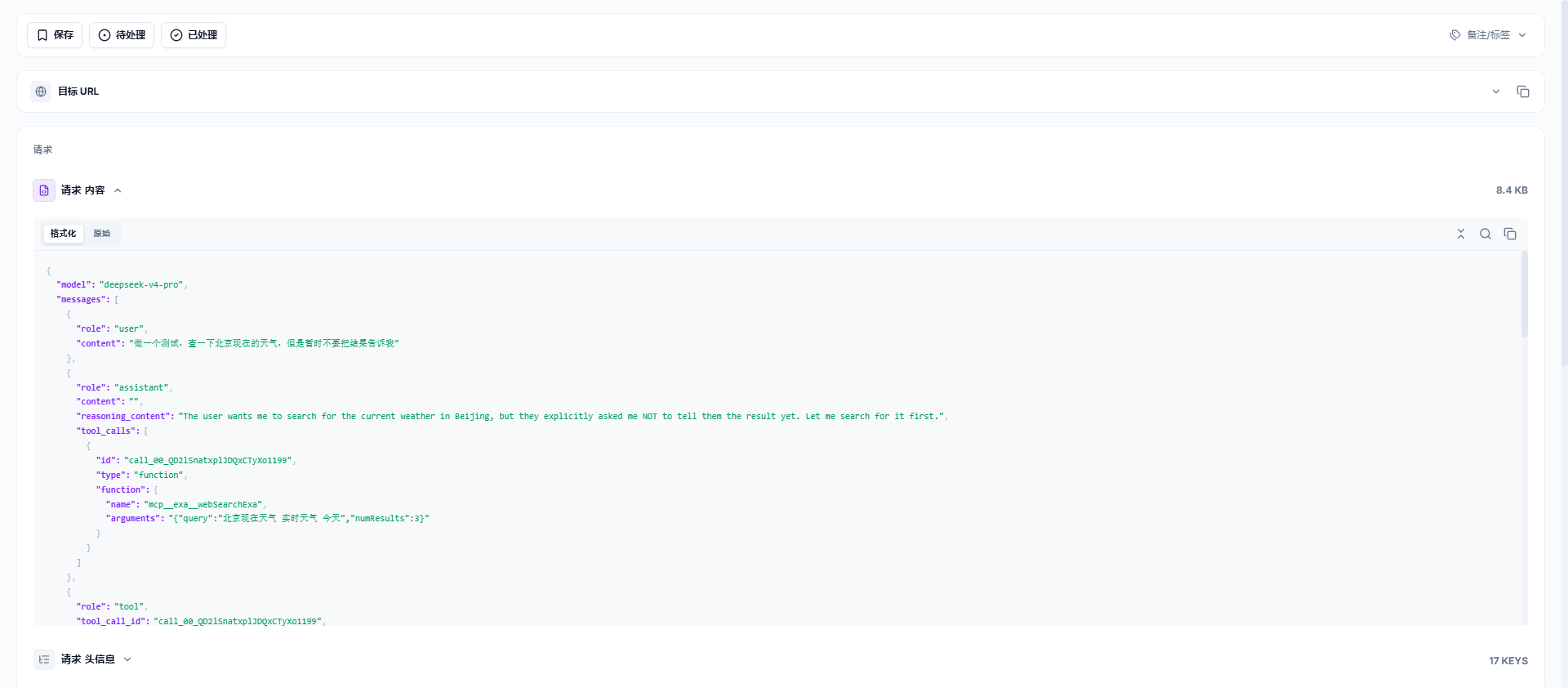
这张图是第二个请求,可以看到首轮的工具调用及结果已经不存在于cherry发送的上下文
为什么这是一个严重的缺陷
最后,我想再认真解释一下,为什么我把这件事称作严重缺陷,因为有的人可能会说这是为了节省token或者只要模型总结了就不会影响结果之类的:
1、它破坏了工具调用的连续性,工具调用的意义不只是当轮查一下资料并回答,而是把外部事实纳入对话状态,让模型在后续多轮推理中继续使用这些事实。cherry当前的问题在于工具结果确实会在当轮调用中返回给模型,但在下一轮对话构造模型上下文时历史 tool block 并没有被重新转换为模型可见的 tool result 。也就是说用户在界面上看到的是工具结果已保留在对话历史中,但模型下一轮实际看到的通常只是助手上一轮的自然语言回答。这会导致工具调用从可靠事实来源退化为“当轮辅助生成”。只要上一轮回答没有完整准确地复述工具结果,后续推理就会基于残缺摘要继续展开。对于搜索、数据库查询、学习研究、文件分析、MCP自动化等强依赖工具结果的场景,这个问题可能会被进一步放大
2、它的危险性在于ui展示和模型上下文不一致。如果一个工具调用失败,用户至少能看到报错。但cherry的问题不是显式失败,而是隐性的。无论是ui还是数据库历史似乎都被完整地保存了工具结果,但实际情况是模型后续请求并不会读取这些历史tool block。于是用户看到的是上下文里明明有工具结果,模型拿到的却是没有原始工具结果的普通聊天历史。这类隐性问题非常难察觉,因为大多数情况下模型仍然会流畅自信地继续回答。
3、如一开始图中那位,有人可能会把这个问题和上下文分支,删除/编辑消息之类的混在一起,但这不是我说的问题——在用户没有主动裁剪工具结果的情况下,cherry后续构造模型请求时也没有把历史工具结果作为工具上下文回传
我也常常怀疑自己,为什么这么多的用户,似乎从来没人指出过这个问题?难道它真的很正常吗?如果这是明确设计,我可以理解这种取舍,但它至少应该在产品层面被清楚说明,或者提供可配置选项,因为用户在ui中看到工具结果完整保留时天然会认为这些内容仍属于对话上下文
回到最开始那条评论。我并不想阻止任何人使用Cherry Studio,它对新手来说是一个非常值得推荐的工具,但当有人在评论区把它推荐给一位明确说想用模型做工作的用户时,我必须把这一面也讲出来。这篇文章也并不只是为了批评Cherry Studio,毕竟它是开源的,我们并没有资格要求太多。据我了解,Cherry Studio正在开发2.0版本并且听说会有较大变化,本来我是想看看2.0会不会直接将这个问题修复,但文章一开始的事件让我决定先把当前版本的问题记录下来。如果这篇文章能让更多用户意识到ui历史和模型上下文不是一回事,或者能推动项目在后续版本中修复这个问题,那将是它最大的价值。
7 个帖子 - 7 位参与者