智谱GLM团队联合TileRT团队于今天正式推出了GLM-5.1高速版API(GLM-5.1-highspeed),其模型输出速度达到每秒400 tokens,刷新了当前全球大模型厂商API的速度上限。该服务目前已面向智谱MaaS平台的部分企业客户开放,主要用于解决AI编程、实时交互以及实时语音等对响应延迟要求极高的生产场景痛点。
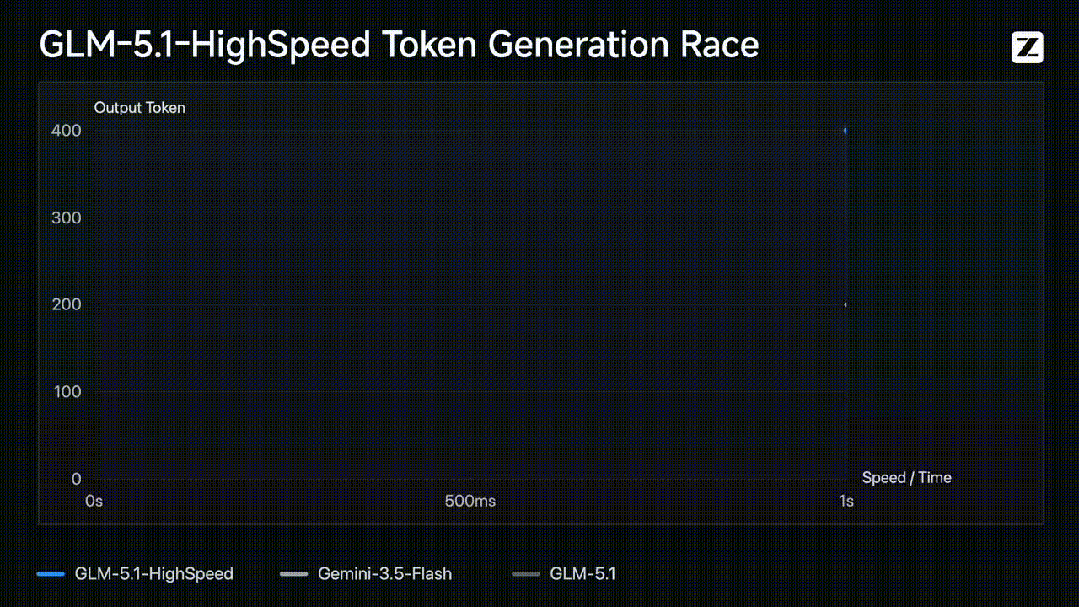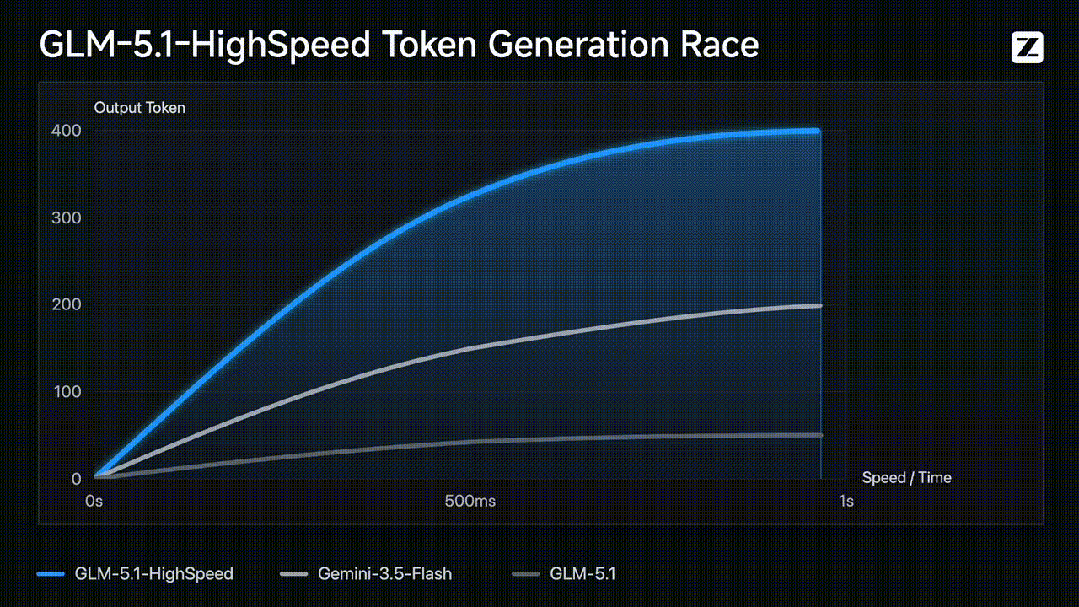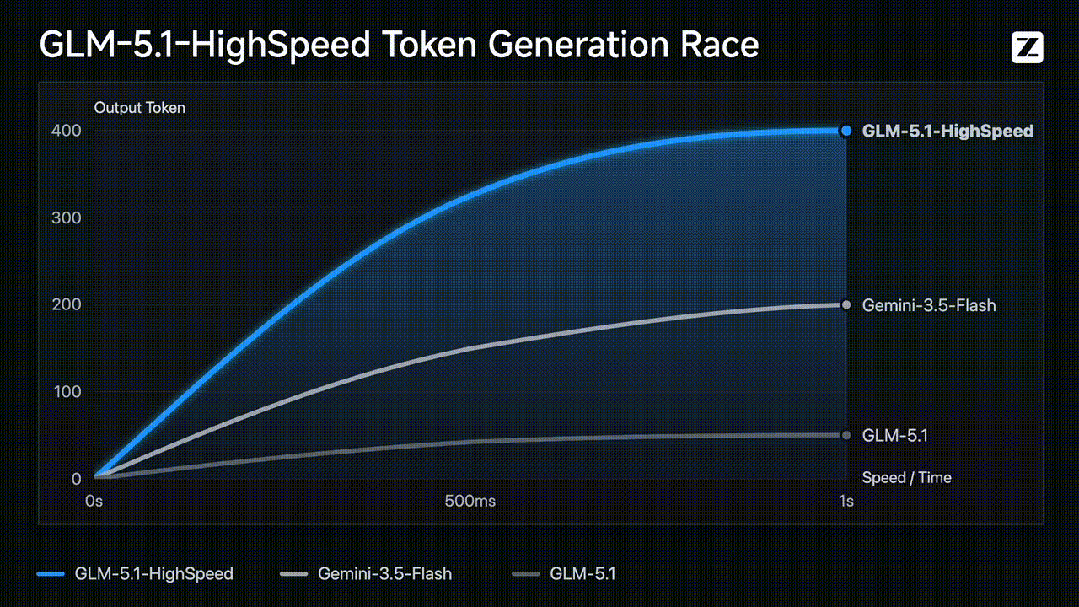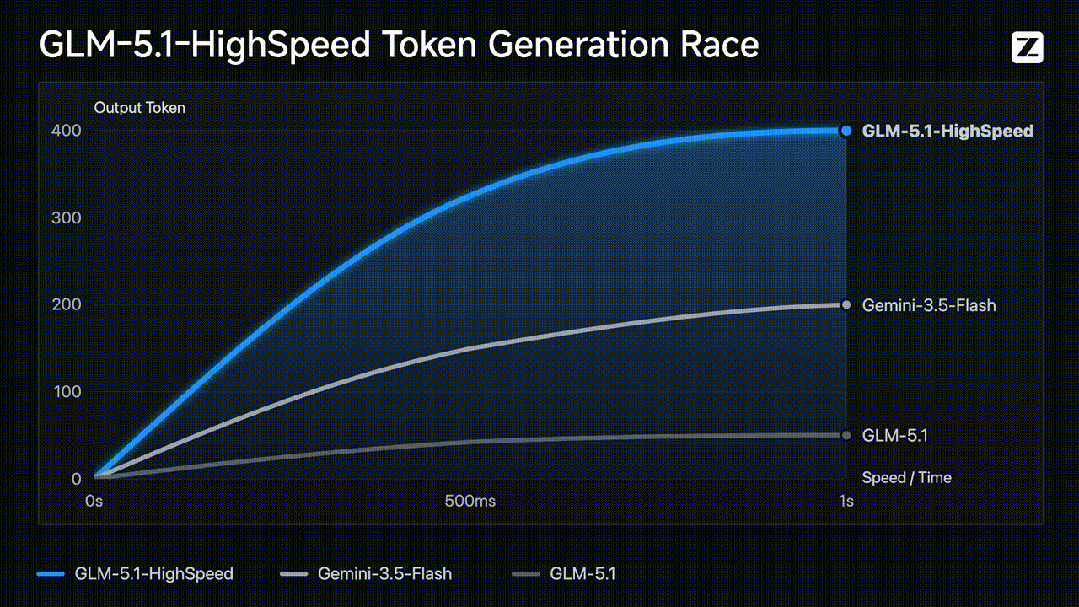
与过往通过缩减模型体积来换取速度的轻量级模型不同,GLM-5.1高速版在完整保留旗舰级大语言模型能力的前提下实现了极低延迟,打破了行业中高性能与低延迟不可兼得的惯例。在实际工程测试中,该模型在长程任务中表现出极高的实时协作能力,不仅能在30秒内完成复杂网页处理,还支持在多智能体协同场景下瞬间调度50个不同人格并行回答。在代码开发、3D地图瞬时建模等高频交互场景中,该模型能够实现即问即答的无缝反馈。
这一速度突破的核心在于双方联合打造的TileRT高性能推理引擎。技术团队针对硬件物理极限与主流推理框架的调度瓶颈,重写了核心推理路径。TileRT彻底抛弃了运行时层的动态调度,在编译期将整个计算图静态编排为一个常驻显卡的 persistent Engine Kernel。通过将计算、异步输入输出与通信全部拆解为Tile级微任务,算子之间的中间结果直接在寄存器和缓存中直传,从而消除了主机调度与跨算子同步的开销,确保了在多卡高并发场景下拥有稳定可用的生产级超低延迟。

GLM-5.1-HighSpeed - 智谱AI开放文档
 tilert.ai
tilert.ai
速度:大模型推理的下一个 Scaling Law
深度解析 TileRT 高性能推理引擎及 GLM-5.1 生产级实践。
10 个帖子 - 8 位参与者
来源: LinuxDo 最新话题查看原文