去年 MathArena 发布了 MathArena Apex 和 Apex Shortlist 测试集,如今 GPT 5.5 已经解决了 Apex 测试集的最后一题。
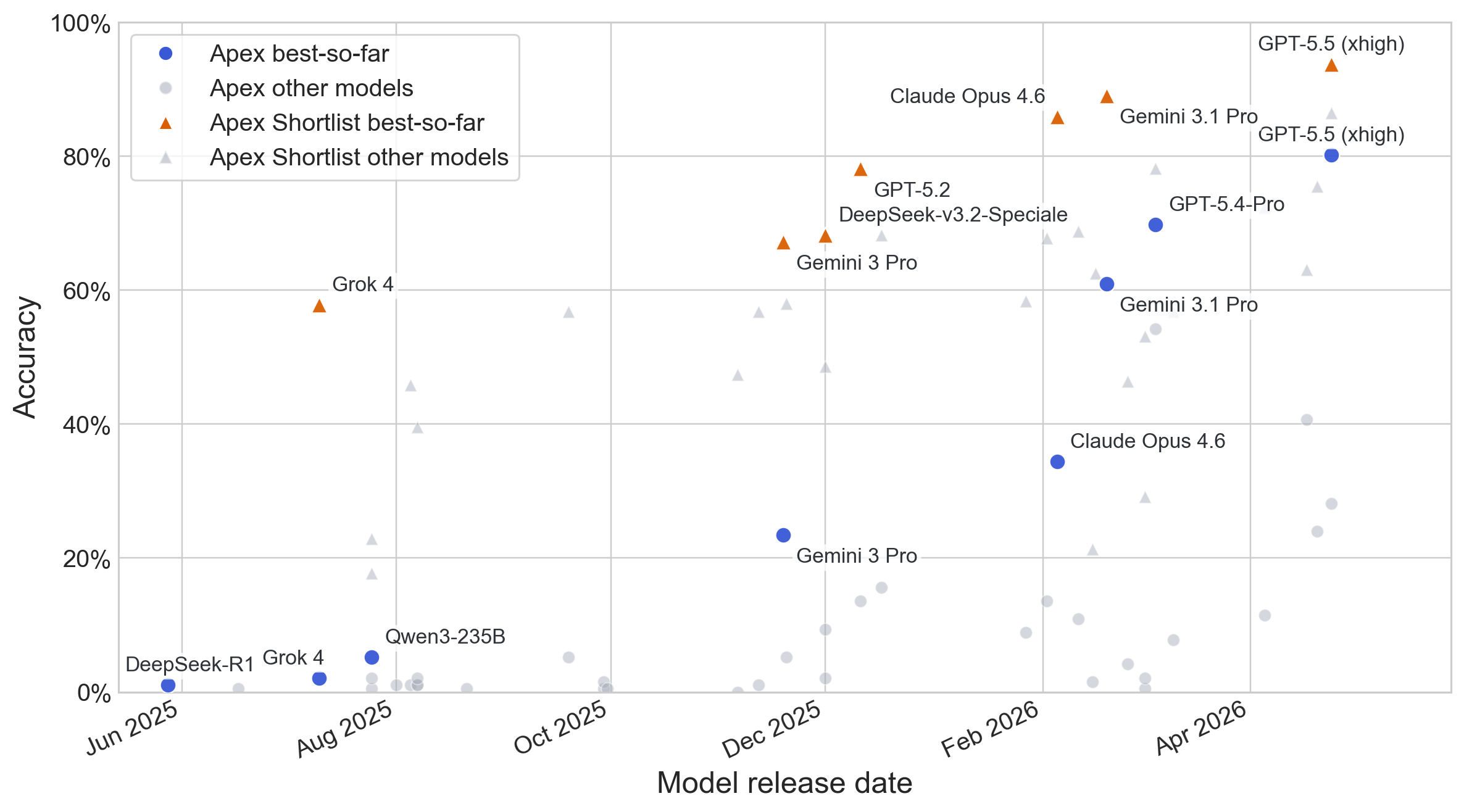
Apex 和 Apex Shortlist 模型得分率随时间的变化
但是该测试集发布至今已有近一年的时间了,MathArena 怀疑可能存在数据污染,于是准备构建 Apex 测试集的第二代。MathArena 选取了 176 道符合条件的最终答案题目,并对每道题目运行了四次 Gemini 3.1 Pro。结果显示:162 道题目在四次尝试中均被求解,其余 14 道题目至少被求解了一次。因此,没有题目符合 Apex 最初的收录标准,而 Apex Shortlist v2 的候选题目数量太少,不足以单独发布。MathArena 现在认为竞赛题仍然有助于追踪小型模型的进展,并评估学术研究中的新方法。
MathArena 建议未来的基准测试应侧重于其他形式,例如证明评估、研究数学以及正确性之外的性质。
原文 Farewell to Final-Answer Competition Problems as Frontier Benchmarks
3 个帖子 - 2 位参与者
来源: LinuxDo 最新话题查看原文