起因
去年我在使用 Roo-Code 的时候,发现插件在读取自己一个含注释的 Python 文件时,任务莫名其妙卡死了,一开始百思不得其解,后来打开 Debug 工具,
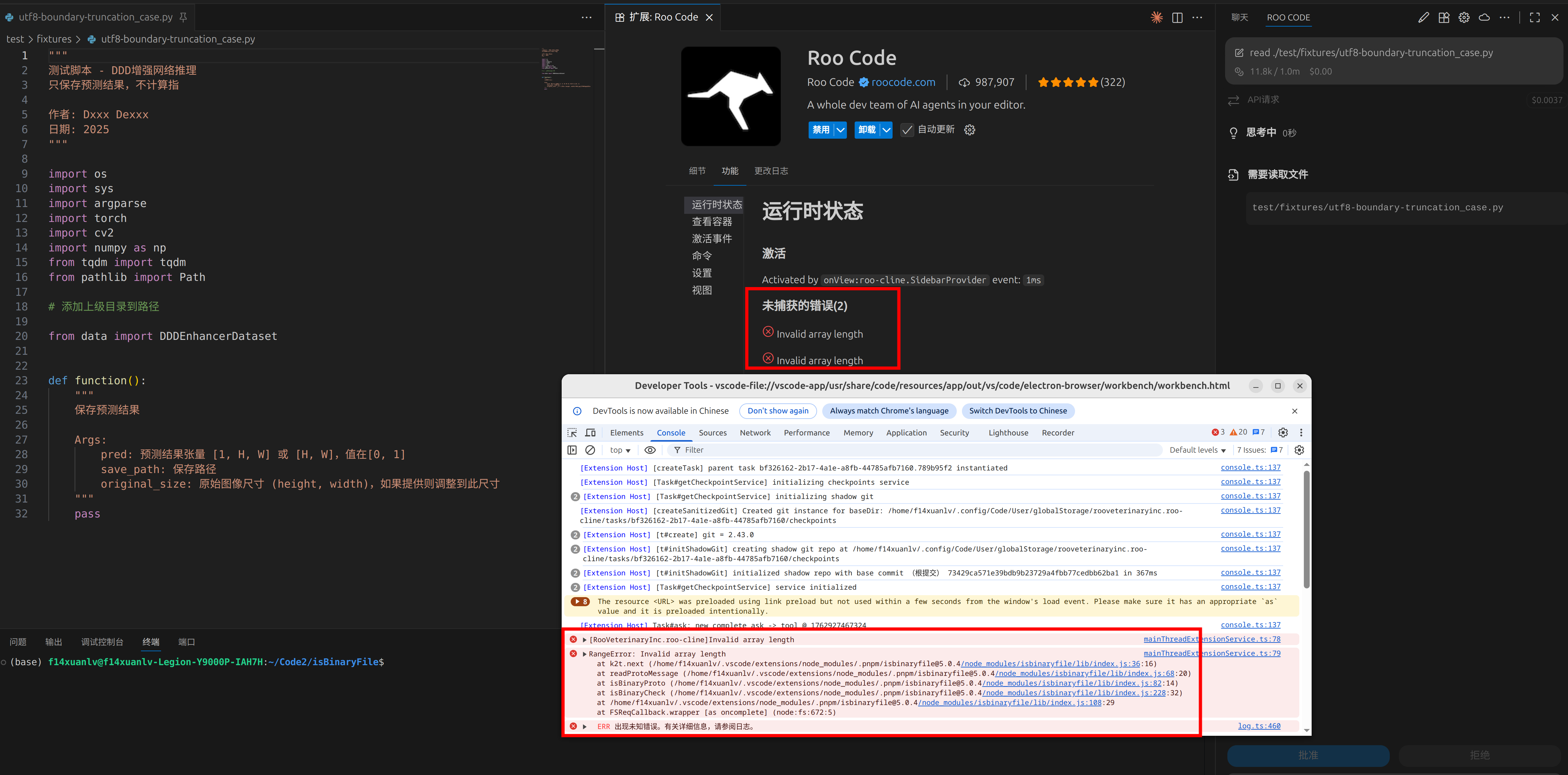
才发现报错来源点来自一个叫做 isbinaryfile 的 npm 包
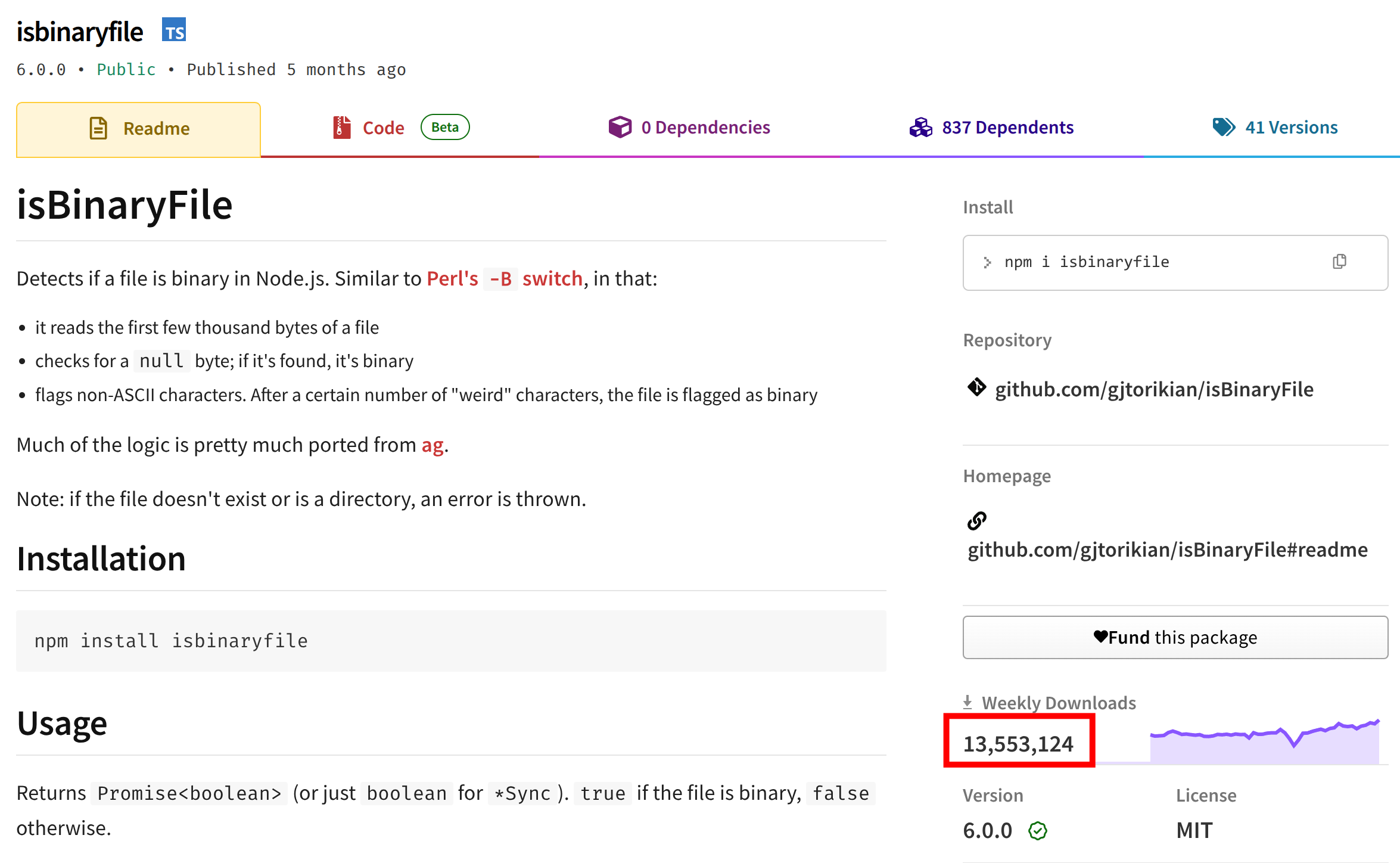
好家伙,全版本周下载量有 1355 万,我判断这是基础设施依赖工具,所以这里有 bug 的可能性应该较低,问题应该出现在 Roo Code 本身上,可能以什么错误的方式调用了这个包函数。
于是我分析了 Roo-Code 相关源代码个遍,都没找出 Roo-Code 本身相关代码有什么问题 ![]()
没办法,那问题只能出在 isbinaryfile 包本身身上了,于是我又转向去分析 isbinaryfile 包的源码,一分析还真给我发现出问题来了。
Bug 的本质:UTF-8 多字节序列在缓冲区边界被截断
isbinaryfile 判断一个文件是不是二进制的核心思路其实很简单:
- 读取文件前 512 字节(
MAX_BYTES)到 buffer 中 - 遍历这些字节,统计"可疑字节"(非 ASCII、非合法 UTF-8 的字节)的数量
- 如果可疑字节数超过阈值(或满足
suspiciousBytes > 1且看起来像 protobuf),就判定为二进制
逻辑本身没问题,问题出在边界检查上。
UTF-8 是一种变长编码:
- ASCII 字符:1 字节
- 拉丁扩展等:2 字节(首字节 0xC0-0xDF)
- 中日韩字符:3 字节(首字节 0xE0-0xEF)
- Emoji、生僻字:4 字节(首字节 0xF0-0xF7)
isbinaryfile 遇到多字节首字节时,会先做边界检查再验证延续字节(源码 line 239/244/250):
// totalBytes = Math.min(bytesRead, MAX_BYTES) = 512
if (fileBuffer[i] >= 0xc0 && fileBuffer[i] <= 0xdf && i + 1 < totalBytes) { /* 2 字节 */ }
else if (fileBuffer[i] >= 0xe0 && fileBuffer[i] <= 0xef && i + 2 < totalBytes) { /* 3 字节 */ }
else if (fileBuffer[i] >= 0xf0 && fileBuffer[i] <= 0xf7 && i + 3 < totalBytes) { /* 4 字节 */ }
关键问题:边界检查用的是严格小于 i + N < totalBytes,这意味着多字节序列的最后一个字节必须严格落在索引 < 512 才能通过校验。换句话说:
举个例子,假设我的 Python 文件长这样:
[前 510 个 ASCII 字符][中][其他内容...]
↑
"中"字 = 0xE4 0xB8 0xAD(3 字节)
位于位置 510、511、512
但 buffer 只读了 0~511,位置 512 根本没读进来!
此时 i = 510,执行 i + 2 < totalBytes → 512 < 512 → FALSE,验证逻辑被跳过:
i=510:0xE4 被记为可疑字节(suspiciousBytes++)i=511:0xB8 落在 0x80-0xBF 范围,不匹配任何 UTF-8 首字节模式,也被记为可疑字节- 循环结束
一个"骑墙"的汉字贡献了 2 个可疑字节,刚好踩中代码末尾的临界判断:
// 源码 line 277-279
if (suspiciousBytes > 1 && isBinaryProto(fileBuffer, totalBytes)) {
return true; // ← 文件被判定为二进制
}
这就是为什么 Roo-Code 在读取我那个前几行有中文注释的 Python 文件时会异常——它把我的源代码当成二进制文件拒绝处理了 ![]()
复现条件总结
要触发这个 Bug,需要同时满足:
- 文件是 UTF-8 编码的文本文件
- 在前 508-511 字节这个狭窄的位置区间内
- 恰好出现了一个 2/3/4 字节的多字节 UTF-8 字符
- 且这个字符的末尾字节越过了 512 边界
- 而且这个 bug 是完全静默的——你不会看到任何报错,只会看到上层工具行为异常(卡死、跳过文件、读不到内容……),其次纯英文开发者遇到这个问题的概率很低。
综上分析解释了为什么这个 bug 存在了这么久也没人发现。
修复思路
我的修复方案是多读 3 个字节。
核心思想是把"扫描范围"和"验证范围"两个概念分开:
// 验证范围:515 字节(多读 3 字节用于跨边界验证)
const totalBytes = Math.min(bytesRead, MAX_BYTES + UTF8_BOUNDARY_RESERVE);
// 扫描范围:保持原来的 512 字节
const scanBytes = Math.min(totalBytes, MAX_BYTES);
for (let i = 0; i < scanBytes; i++) {
// UTF-8 验证可以访问到 totalBytes(515)
if (fileBuffer[i] >= 0xf0 && fileBuffer[i] <= 0xf7 && i + 3 < totalBytes) {
// ✅ 位置 511 时:511 + 3 < 515 → TRUE,可以正常验证!
}
}
为什么是 3 字节?因为 UTF-8 最长就是 4 字节,首字节 + 最多 3 个延续字节,所以多预留 3 字节就足够覆盖所有"骑墙"情况。
测试用例
我构造了 7 个测试文件,把 2/3/4 字节 UTF-8 序列在 508/509/510 三个边界位置的所有组合都覆盖了一遍:
文件 描述 修复前 修复后 508A-4byte.txt 4 字节序列 @ pos 5087 个文件里,4 个在修复前会被误判为二进制,修复后全部正确识别为文本。
合并
PR 提交后,作者 gjtorikian 2 天就 merge 了,并以 5.0.7 版本发布。
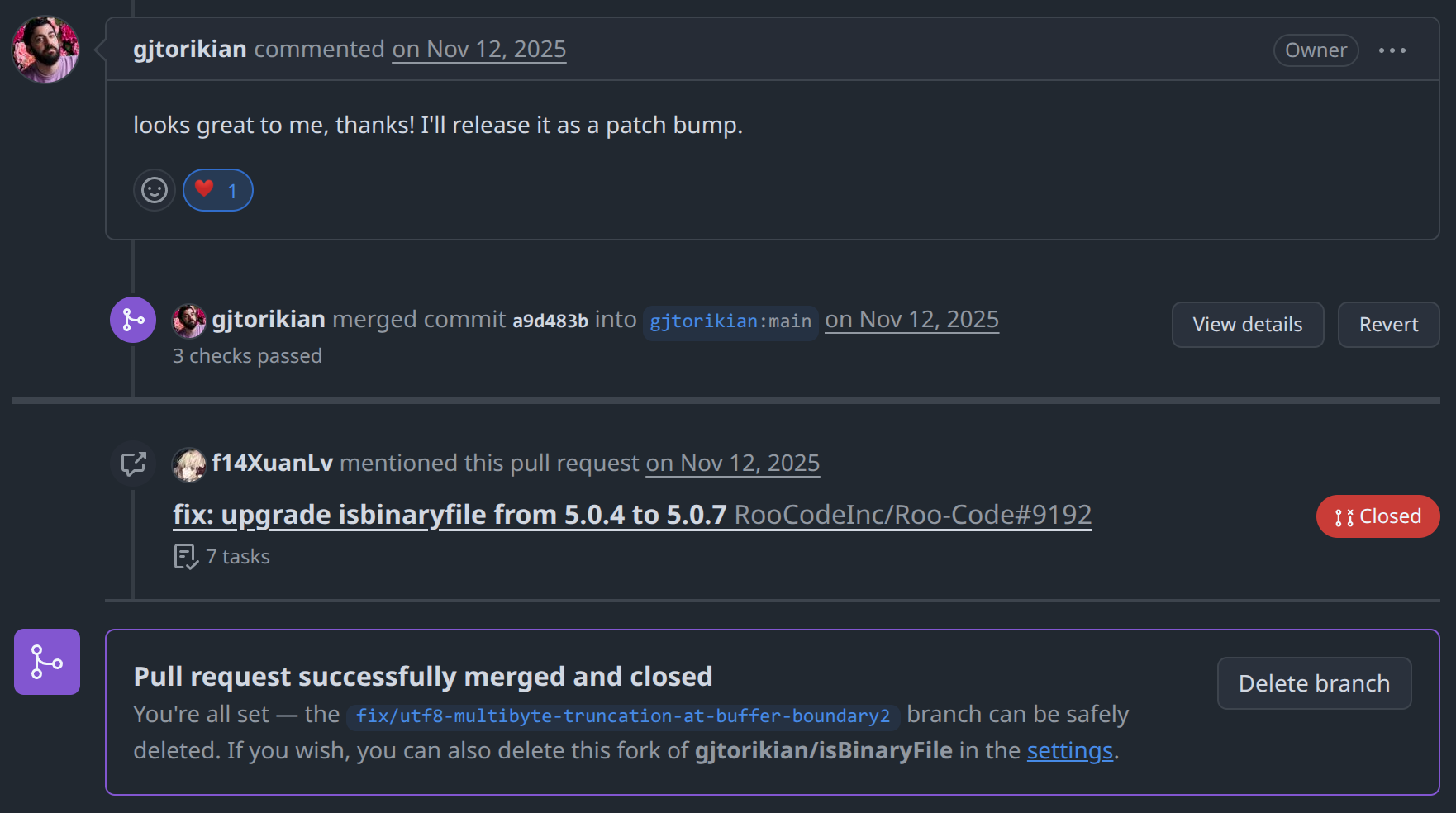
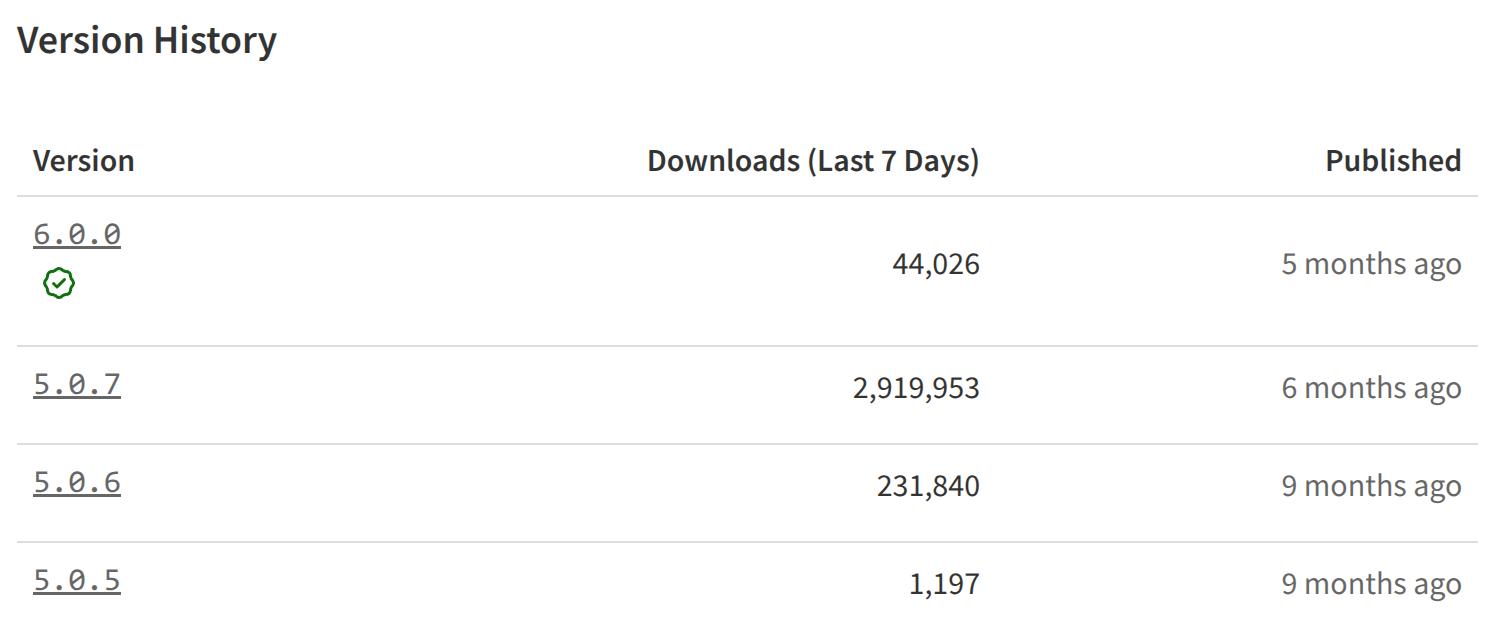
5.0.7 作为我修复的版本也有接近 300w 的周下载量,能有这样的影响力还是高兴的 ![]()
最终的 PR 信息写在 isbinaryfile#91
继续修复上游项目
之后我顺手给 Roo-Code 也提了个 PR,想把 isbinaryfile 的依赖版本从 5.0.4 升到了 5.0.7,结果Roo-Code团队基本不鸟我 ![]()

估计是那个时候 Roo-Code 也算半个商业软件了,团队接收非核心成员的 PR 比例极低,我看都是 Bot 在写 PR。
最后最近 Roo-Code 原团队宣布放弃该插件,全面转向云端 Agent,Roo-Code 的持续更新工作转移到了 Zoo-Code 这个 fork 版本,维护由新的成员接替,我也是终于把这个上游项目修了 Zoo-Code#88
闭环。![]()
1 个帖子 - 1 位参与者