- 我的帖子已经打上 开源推广 标签: 是
- 我的开源项目完整开源,无未开源部分: 是
- 我的开源项目已链接认可 LINUX DO 社区: 是
- 我帖子内的项目介绍,AI生成、润色内容部分已截图发出: 是
- 以上选择我承诺是永久有效的,接受社区和佬友监督: 是
以下为项目介绍正文内容,AI生成、润色内容已使用截图方式发出
这几天使用Pi Agent + deepseek-v4-pro做了项目开发,发了错误截图给他,结果给我回了模型不支持解析图片。
问了AI,国内外有一些模型是能够识别图片的,而且免费或者有免费额度,比如Gemini 2.5 Flash,GLM-4.6V-Flash,
基于此,自己决定开发一个skill,当大模型识别不了图片的时候,用skill去识别。
当然如果用的是opus4.7或者gpt-5.5这种模型的话,也就没有必要用这个skill,另外随着国内大模型多模态的普遍化,这种skill也会失去它的意义。
项目地址 github.com
GitHub - penfick/skills: some agent skills
some agent skills
虽然现在就一个skill,但也放到了skills目录下边了
skill名称vision-support
安装方式npx skills
npx skills add https://github.com/penfick/skills --skill vision-support -g -y
npm
npm install -g vision-support
安装后需要初始化,配置一个provider,apikey,
# Git Bash / Mac / Linux 终端
node ~/.agents/skills/vision-support/scripts/vision.mjs init
# Windows PowerShell
node "$HOME\.agents\skills\vision-support\scripts\vision.mjs" init
# npm 安装
vision-support init
配置完成后,就可以在cloudcode,Pi agent中使用了
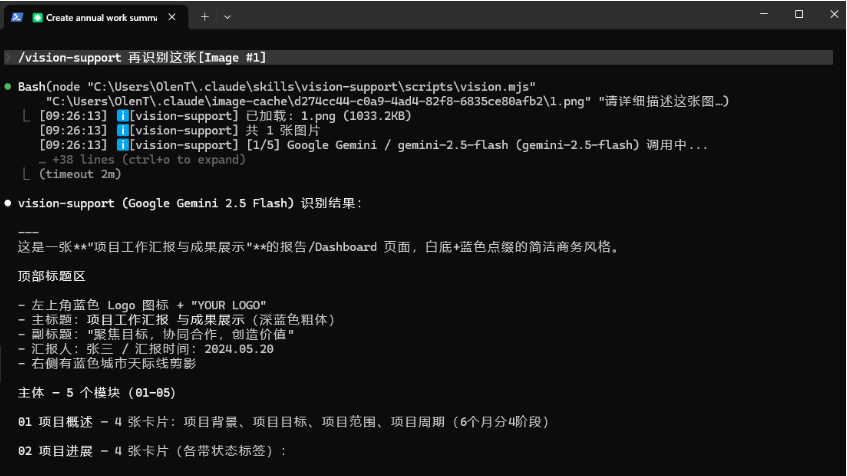
第一次发开源推广,如有问题,请大佬们及时指正 ![]()
2 个帖子 - 2 位参与者
来源: LinuxDo 最新话题查看原文