在输出思维链时,在v2w层后加一个随机偏移,偏移到另一个token,同时输出这个偏移值,要求在下一次推理的时候把偏移值数组也带回来。
这样在下一次推理的时候服务侧就可以根据偏移后的token和偏移值反求原token,并且向用户隐藏了真正的思维链,只要v2w的算法没有被破解就是安全的。
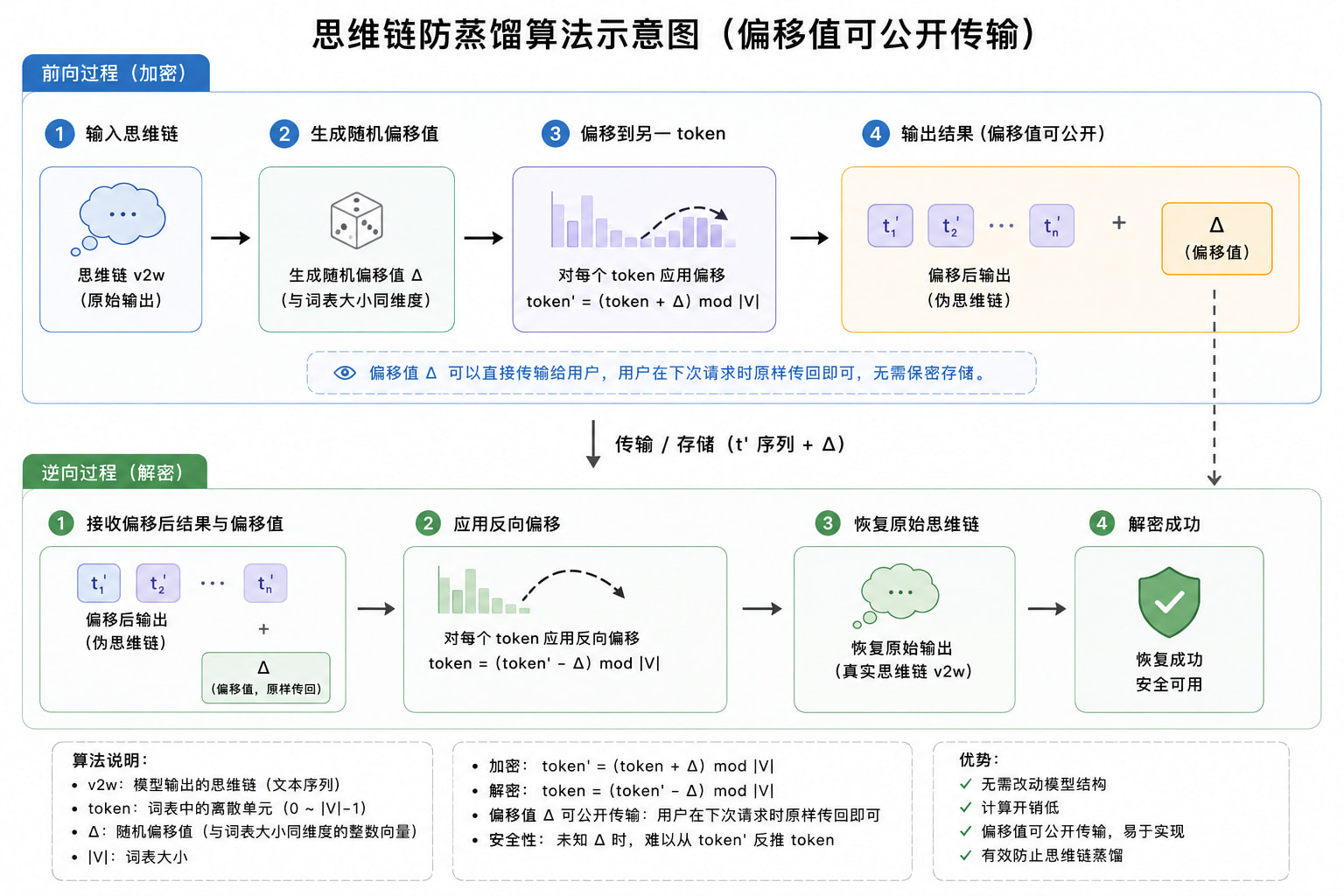

不过想了想在乎思维链的厂商现在的策略是直接隐藏/用一个小模型概括思维链(gemini/gpt),所以可能这个方法也没什么实际价值,可以节省厂商缓存思维链或者概括的成本?
从这个方法发散,还可以想到两个使用场景:
-
agent加密:如果AI面向的是agent这类偏向干活而不是聊天的用途,我们甚至可以将非思考部分也一起加密,只明文的本地工具调用和最终结果汇报。
-
面向开源模型的中转站防窥,可以使用对称防中间人攻击的方式在源站和用户之间协商密钥,通过密钥生成偏移值,然后request和response全程使用偏移值加密,用户侧使用开源模型的v2w算法从加密token反求真实token。
4 个帖子 - 4 位参与者
来源: LinuxDo 最新话题查看原文