相信前段时间比较火的LLM WIKI项目,利用AI工具+Obsidian来处理文档,里面就提到了Obsidian web clipper这个插件。
之前在使用这个插件的时候就只是直接用默认配置给抓取文章了,最近有在看一些英文的文章,苦于一些专业词汇,并且还希望能中英文对照的阅读学习,就搞了一个适配插件的AI处理配置。
本身这个Obsidian的chrome插件就是内置ai工具的,在解释器里可以利用ai模型来处理文本。于是就弄了一套配置如图:
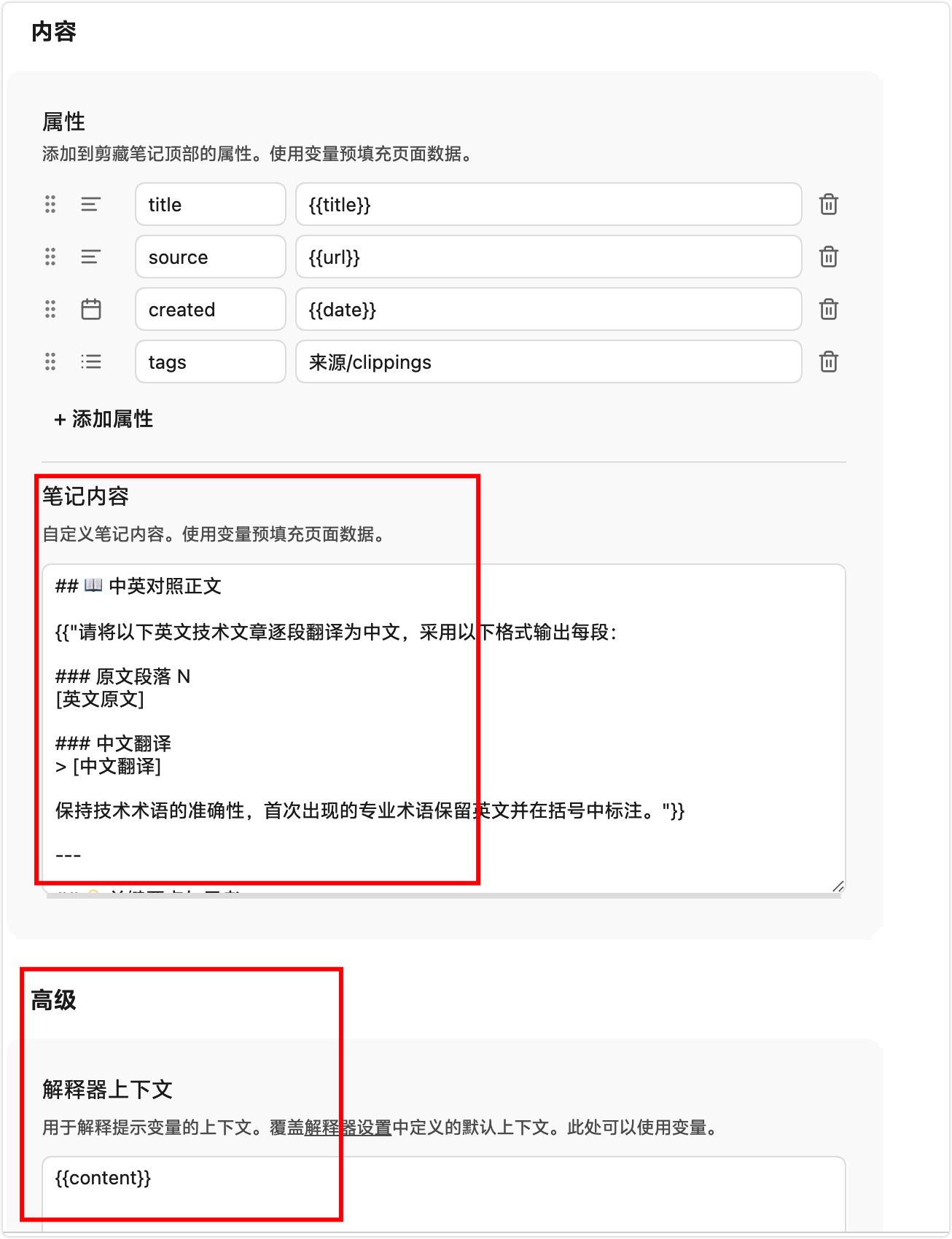
## 📖 中英对照正文
{{"请将以下英文技术文章逐段翻译为中文,采用以下格式输出每段:
### 原文段落 N
[英文原文]
### 中文翻译
> [中文翻译]
保持技术术语的准确性,首次出现的专业术语保留英文并在括号中标注。"}}
---
## 💡 关键要点与思考
{{"基于文章内容,提取 3-5 个关键学习要点,并给出个人思考/延伸问题的建议。用中文输出。"}}
---
## 📚 原文存档
{{content}}
这样保存回来的文章就有一个中英文的对照查看了。

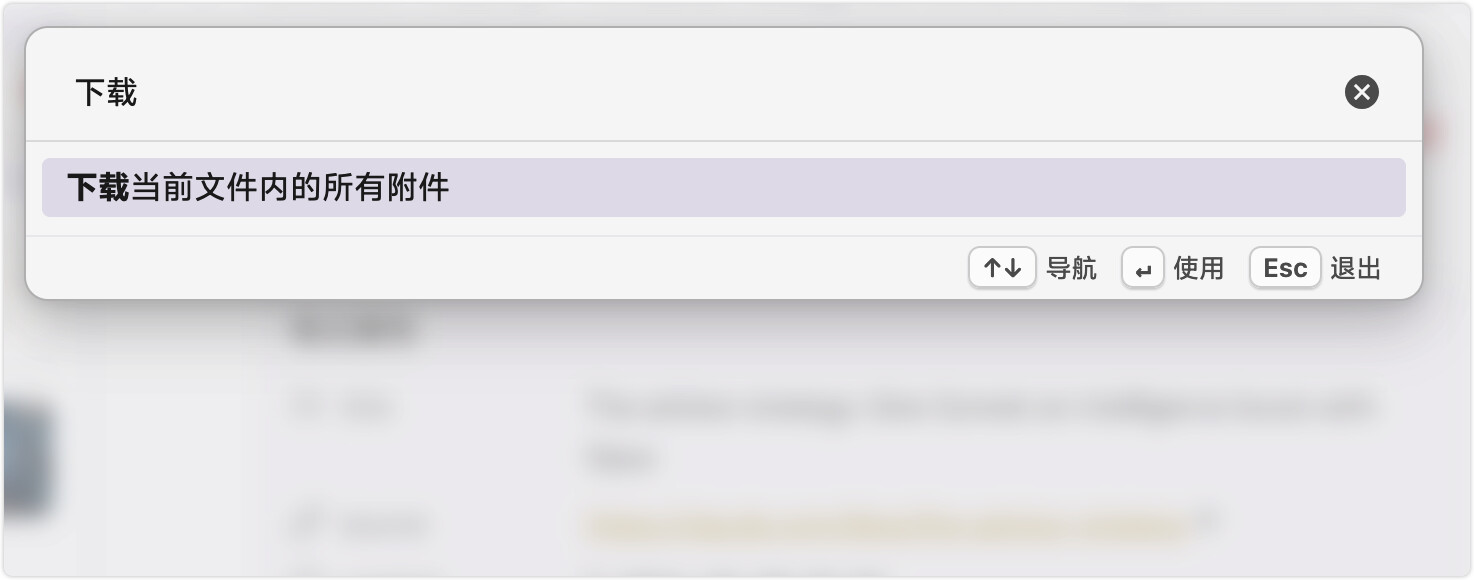
保存到库里的文档可以再用内置工具把网页图片一键下回来,避免原文失效。
6 个帖子 - 4 位参与者
来源: LinuxDo 最新话题查看原文