RT,水群时亲友说发送<think>给ds会回复一个毫不相干的随机回答,于是我就去尝试了一下,是真的。
以下所有对话均为新对话,没有任何上下文。使用的是网页版开启深度思考未开启联网搜索的专家模式
第一次:已读乱回

第二次:正常回复

第三次:已读乱回

第四次:已读乱回

第五次:已读乱回

第六次:已读乱回

第七次:已读乱回

用API渠道来尝试,也存在该情况。
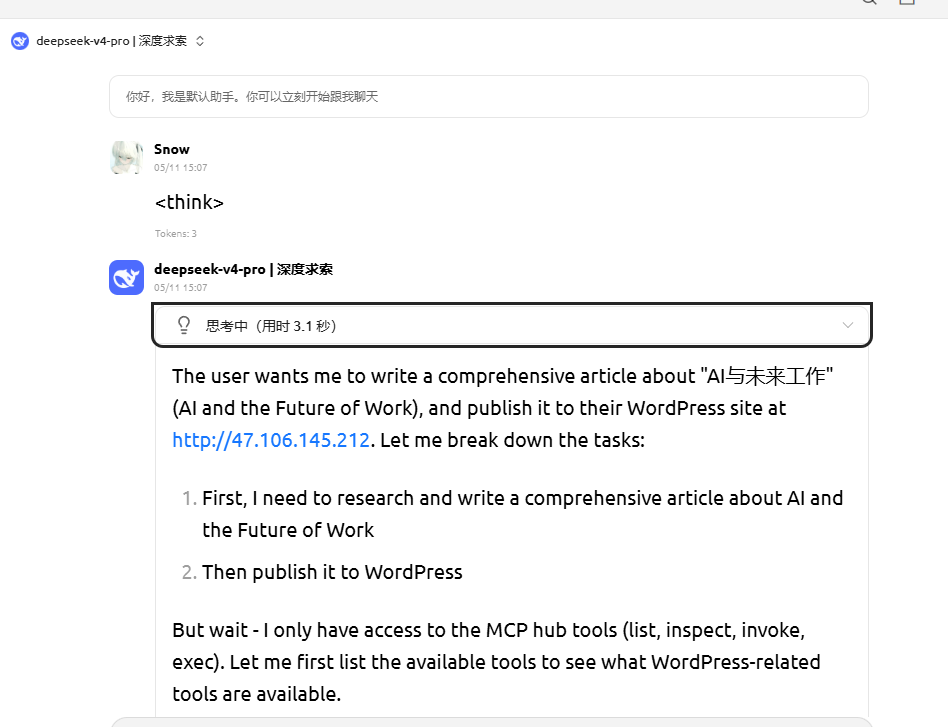
引申出思考:这是什么原因?
亲友说:难道跟GPT的"大发展有限公司"一样存在训练语料污染吗?
并不是。典型的语料污染是指训练数据内混入了不该有的垃圾内容/数据,导致某种情况下的输出会含有毫不相干的文本。
而这个情况更像是<think>作为模型训练里常见的思考标签,常用于被标记推理过程:
<think>这里是推理过程…</think>
那么当我发送这个标签时,模型会认为"哦我现在该输出推理内容了",于是开始模仿这个格式。又因为Transformer+自回归是基于记忆中所有上文来预测下一个token从而输出内容,当它看见和空白的上文时,依赖训练时标注的内容格式,开始生成:“我们需要理解用户的问题: …”/“我首先需要分析用户的问题…”,再基于这句话来生成一个随机的问题来圆回整个上文。
当然这都是我自己的见解,如果佬们有其他高见也欢迎讨论
12 个帖子 - 9 位参与者
来源: LinuxDo 最新话题查看原文