[!warning]注:原帖超过编辑时限
从【开源skill】被跨对话/跨agent恢复上下文反复折磨后,我做了个项目本地记忆skill【新版本前瞻】继续讨论:
[!todo]社区开源推广声明
本帖使用社区开源推广,符合推广要求。我申明并遵循社区要求的以下内容:
- 我的帖子已经打上 开源推广 标签: 是
- 我的开源项目完整开源,无未开源部分: 是
- 我的开源项目已链接认可 LINUX DO 社区: 是
- 我帖子内的项目介绍,AI生成、润色内容部分已截图发出: 是
- 以上选择我承诺是永久有效的,接受社区和佬友监督: 是
以下为项目介绍正文内容,AI生成、润色内容已使用截图方式发出
[!check] 版本更新提示:v0.4.0 现已正式发布
已安装的佬友请尽快使用npx skills update recallloom来更新使用新版本!

🧶 RecallLoom
让项目自己记住自己。
把背景、进展、关键决策和下一步留在项目文件里。换会话、换模型、换工具,下一次 AI 协作也能接上当前状态。
![]()
![]()
![]()
![]()
![]()
[!tip]如果觉得对您有帮助,欢迎STAR并推荐给更多佬友!
背景
Hi~ 各位佬友!
距离上次RecallLoom更新已经过去了一段时间,今天终于迎来了RecallLoom的最新V0.4.0版本的正式发布~
这段时间,我在规划、升级新版本的同时,也在和佬友们交流对于RecallLoom的想法、心得、以及使用感受,非常感谢佬友们对本项目的大力支持,同时也很感谢发现问题、为项目迭代提供思路的佬友们!RecallLoom是与大家一同成长的。【详细见原帖讨论】
此外,我也在RecallLoom开发项目、自己的硕士学位论文项目中,真实接入了RecallLoom来辅助项目管理,进行了深度体验,个人感受是真的有在提高项目推进效率并降低了解释成本,我很高兴能和佬友们进一步分享。
给新认识的朋友们介绍一下
[!QUESTION]为什么要做 RecallLoom ?
[!fail] 在使用 Agent 推进长期项目协作时,最磨人的常常是开头要费精力解释项目。
我把上述叫做“重启税”。
不知道佬友是不是已经遇到过下面的情况:
- 换会话、换模型、换Agent,或隔几天回来,就要花时间重新告诉 AI “我在做什么”。
- 新的 Agent 工具能读到仓库里的文件,却不知道哪些事实已经过期、哪些结论仍然有效。
- 平台私有记忆(memory)、聊天记录和项目文件分开存在,关键决策很难跟着项目一起走。
- 项目一做久,“为什么这么做”“现在什么是真的”“下一步该接哪里”最容易丢。
[!success] RecallLoom 就是为了无痛丝滑解决 “项目级记忆 ”和 “接力连续性”
- RecallLoom 从项目级别把本项目的背景、当前状态、关键决策、最近进展和下一步,保存在项目内的受控文件里。下一次换会话、换模型、换工具,或隔几天回来时,新的 AI 工具可以快速先接上当前事实真相,再决定要不要深入历史材料。
这让“记忆”从原来聊天开场时的临时解释,变成项目里可读、可审、可继续维护的工程资产,摆脱“重启税”的烦恼。
[!QUESTION]怎么想到做 RecallLoom ?
其实我发现上述问题早就成为大家普遍的痛点,一开始我也在论坛里找各种各样的解决方案,其中不乏各种Agent级别的记忆系统,还有轻量级的一个markdown文档记录一切的方法。但是,我都觉得不太适合自己推进的一些长期项目。
就拿写论文举例,我是一个典型的经管生,我们的论文不仅涉及到研究问题、论证思路、假设、结论推导等,还涉及模型、数据、实证等过程。一套完整论文的诞生,需要敲定研究方案,确认假设与理论推导逻辑,设计变量定义、模型结构、参数,还要进行实证统计检验,这是个复杂、长期的项目,也需要经历反复推翻、验证、再推翻的过程。
- 如果每次都在一个巨长的session里一直聊下去,本身就不可持续,上下文爆满,反复compact模型幻觉飘到天上去,准确的对话历史也难以高质量召回。
- 如果每次新开一个对话,又不可能无线fork下去,又要费尽心思组织开场白,费一堆时间来解释来龙去脉,我做到哪了?
- 文字写作我喜欢用deepseek V4 pro,如果涉及代码、数据工作,我又要切到codex用GPT或者切到Claude Code,这时候又要解释一大堆背景了。
也是在探索过程中,慢慢确定了如今 RecallLoom 的形态和生态位
—— 它是一个轻量的、文件原生的项目连续性接力SKILL
 30秒开始
30秒开始
1. 安装 RecallLoom
把下面命令复制到终端。
如果你不想处理命令细节,可以把整行交给 Agent 执行:
npx skills add https://github.com/Frappucc1no/recall-loom --skill recallloom
之后需要更新时:
npx skills update recallloom
2. 首次初始化(可选,仅首次)
如果这是第一次在当前项目使用 RecallLoom,需要先初始化项目记忆。
[!TIP]已有
.recallloom/的项目可以跳过这一步。
初始化需要用任意一种显式唤起方式:
如:
1. @recallloom 初始化当前项目
2. 请用 RecallLoom 接管这个项目
3. 请用 RecallLoom 初始化这个项目
4. rl-init
[!info] 首次接入会在项目旁边建立 RecallLoom 的项目记忆目录,用来保存背景、进展、关键决策和下一步。
3. 日常使用:自然语言继续
项目接入后,常用说法很自然:
如:
继续这个项目
先帮我恢复项目上下文
从上次停下的地方继续
记录今天的关键进展
[!info]在已接入的项目里,
继续这个项目会让 RecallLoom 先执行恢复步骤:先读取项目记忆,再进入具体任务。
[!SUCCESS] 日常接力无需每次都写
@recallloom。
4. 熟悉后可用短触发词 (可选)
这些词可以直接发给 AI 工具,作用类似更短的自然语言触发语:
直接输入 你想做什么rl-init
初始化项目记忆,让 RecallLoom 接管当前项目
rl-resume
恢复项目背景、当前状态和下一步
rl-status
查看项目记忆是否完整、是否需要处理
rl-validate
检查连续性文件有没有结构问题
多数时候,说“继续这个项目”就够了;熟悉后再用短触发词提速。
真实效果
眼见为实,下面请看在我的【硕士学位论文】项目中的真实效果:
[!WARNING]多图预警 ( Codex Desktop / GPT-5.5 )
[!check]prompt:“恢复论文进展”
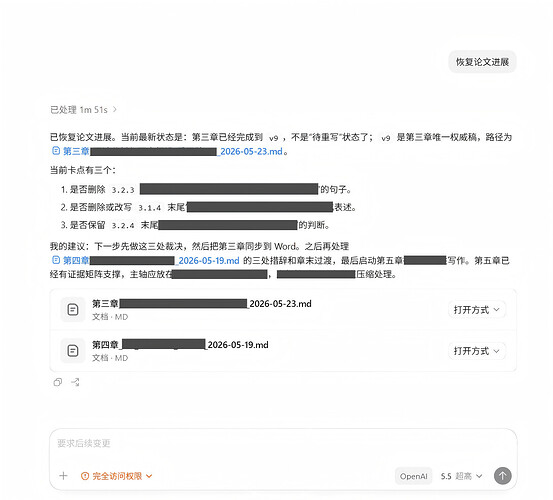

[!check]prompt:“梳理近一个月论文的推进进展,关键结论,以及我推翻了啥?”

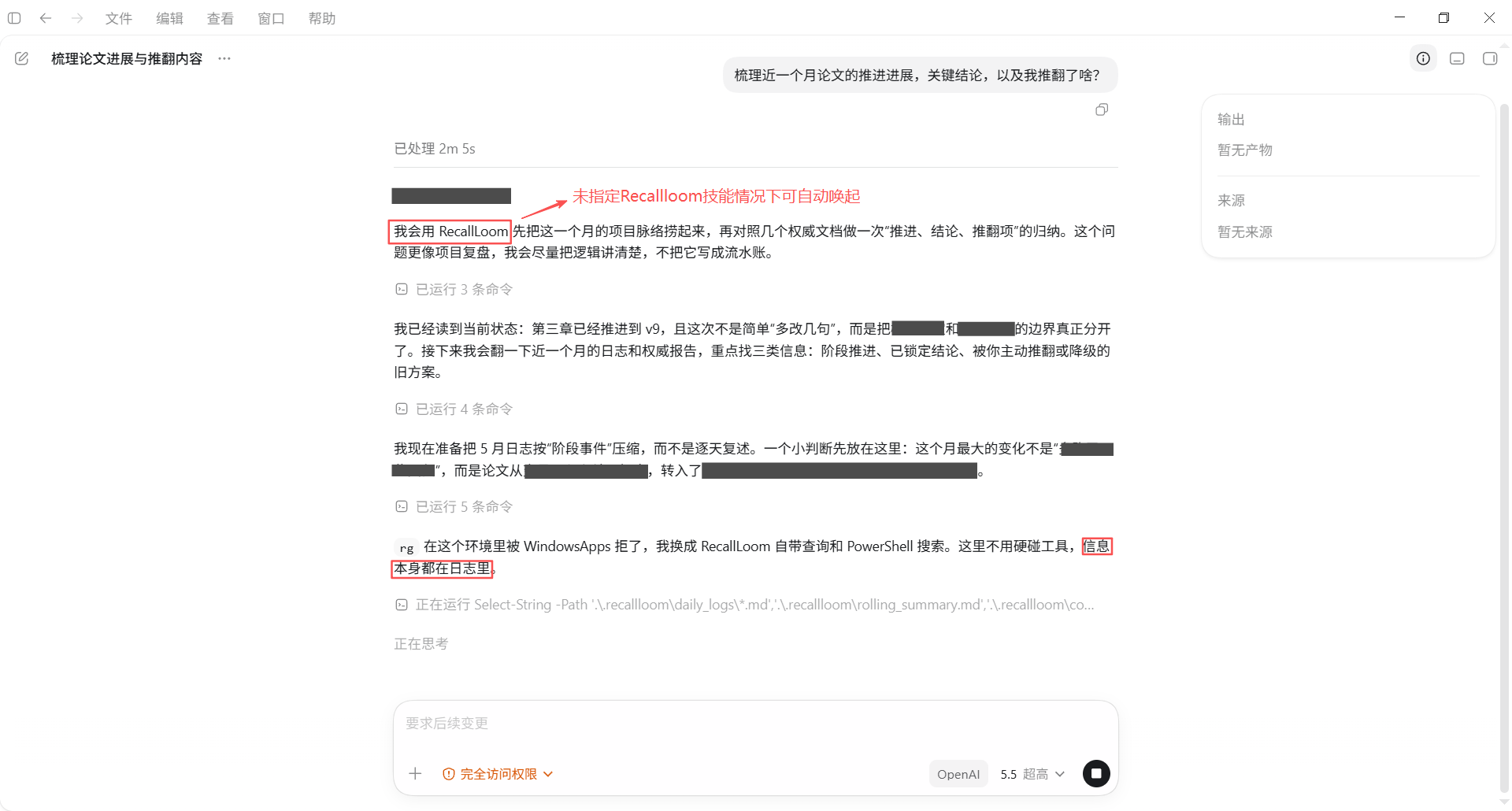




[!check]prompt:“上述是通过recallloom恢复的吗?其帮助有多大”


新版本更新了啥
[!TIP]V0.4.0 (2026-05-24)
更准确的恢复路径、更低摩擦的进展更新、更清楚的写入保护和工具边界
v0.4.0版本比较大的变化是:我优化了逻辑架构,吸收轻量“图记忆”的基本原理,但不至于做成重型“图记忆”数据库或RAG检索。
此举,使得RecallLoom现在能够对写入的记忆附带一个“关系路标”,它可以把与之关联的记忆打上路标,在记忆检索、召回、降级、过时记忆退出的时候,能够更加准确。真正意义上,使用文件原生的形态,以轻量化方案来缓解记忆关联的难题。
详细版本摘要如下:
- 更可靠的项目恢复:优先读取当前状态、活跃判断和下一步,再按需进入背景材料和历史记录,减少旧信息干扰。
- 更顺手的进展记录:更加优化的结构化记录,并提供记录后同步当前状态的标准路径,让“刚刚完成了什么”和“下一步接哪里”保持一致。
- 更安全的长期记忆写入:加强修订检查、新鲜度检查、来源文件边界和临时草稿处理,降低把过期内容或不该沉淀的内容写入项目记忆的风险。
- 更清楚的多工具协作边界:适配Codex、Claude Code、Gemini CLI、OpenCode 等Agent的最新边界,并提供相应的快捷命令入口,但项目事实仍保存在工作区内的 RecallLoom 文件中。
- 更清晰的说明:README、USAGE、SKILL、package metadata 的职责更明确,安装、恢复、更新和可选 native wrappers 的入口更一致。
- 更严格的隐私与输出安全:继续对私有路径、token 形态、元数据和外部来源摘要做 public-safe 处理,减少把本地环境细节带入输出的风险。
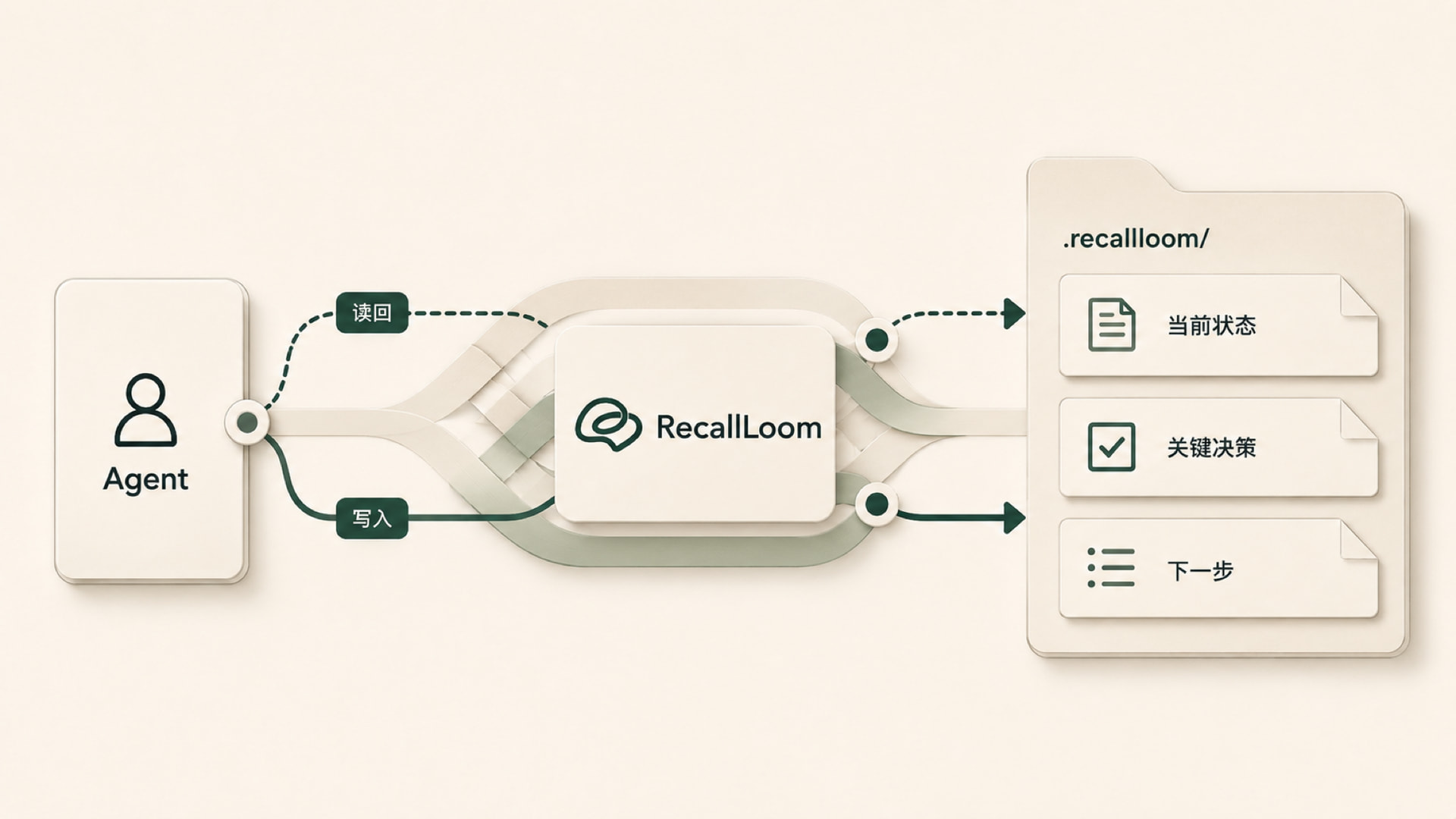
项目接力循环
RecallLoom 的核心模型可以概括成一个 典型项目记忆循环:

特性与工程设计
[!info]本节详细内容请移步阅读 README
特性 带来的价值 低重启税 换会话、换模型或隔几天回来时,先恢复项目状态 更快接力 先看当前摘要、最近进展和下一步,快速进入状态 更省上下文 先读小而准的项目记忆,深查只在需要时发生 跨工具接力 换模型、换会话、换 AI 工具时,项目事实仍跟着工作区走 写入更稳 进展记录、当前摘要和校验动作有明确路径,降低把过期事实写回项目记忆的风险 文件化保存 记忆落在 Markdown / JSON 文件里,可读、可审、可迁移[!TIP]RecallLoom 的价值——更短的恢复路径
少解释、少重读、少猜测,让 AI 工具先接上当前事实。
Github链接
github.com[!SUMMARY]帮我点个 STAR 吧! 这对我是个很好的帮助。
GitHub - Frappucc1no/recall-loom: Portable continuity layer for long-running AI...
Portable continuity layer for long-running AI projects across models, agents, and sessions.
致谢
- 感谢迭代过程中所有提供支持和建议的朋友们
- 感谢各大中转站的GPT资源(我好像花了25亿+Tokens)
1 个帖子 - 1 位参与者