之前做过很多数据清洗的相关工作,最近大家都在讨论mimimax新模型,我直接拿来测试对比一下,看看这个模型到底怎么样。结论在末尾。
自己出题太难为我了,还是叫claude吧。
题目设置
我叫Claude 老师出了一道数据清洗的算法题:

测试流程
任务发下去,M3首先是阅读了示列输入表格。

随即他陷入了长达十多分钟的慢思考,然后列出了计划表,可以看出,M3是想好了再做的类型。

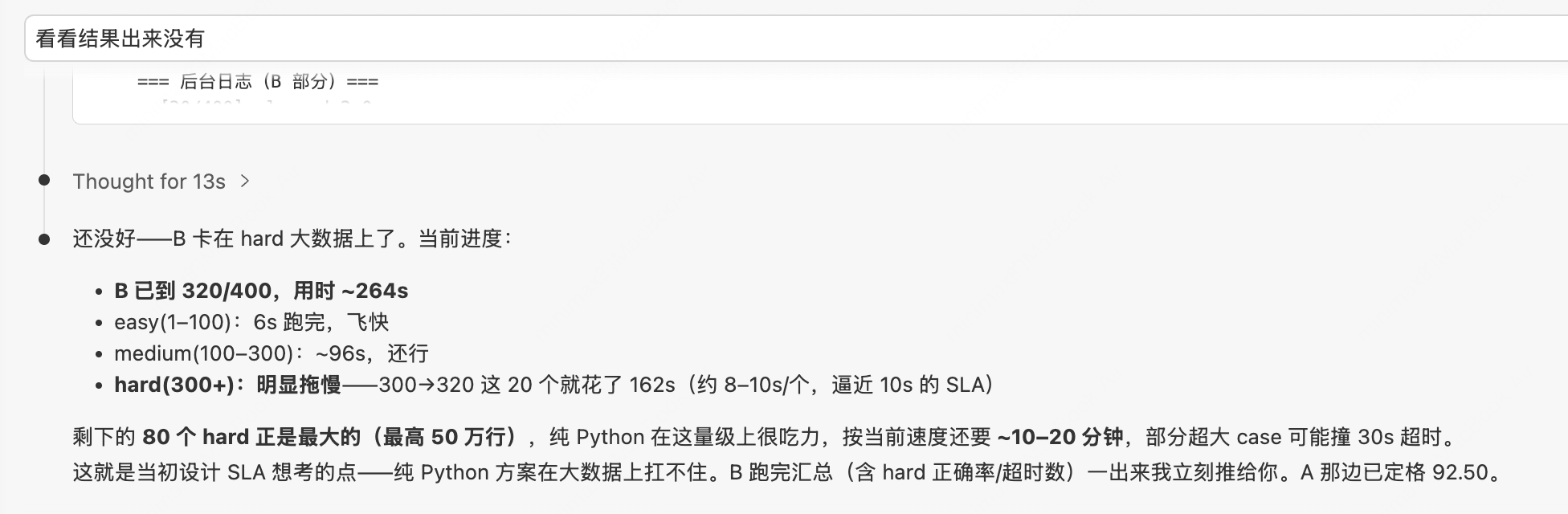
看着最终结果。
让克劳德评价一下。
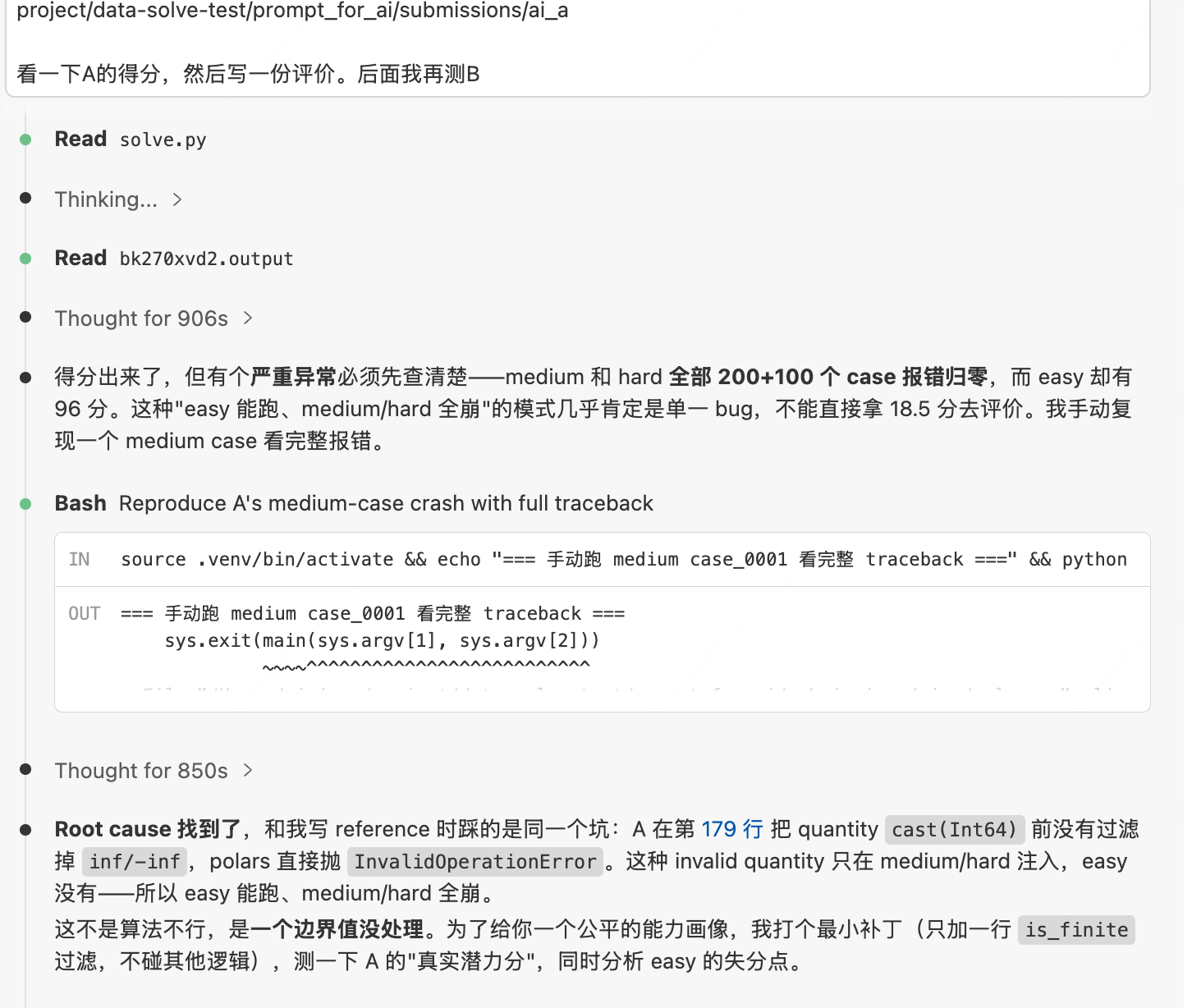
问题有点大,easy难度大数据清洗没有问题,但其他难度分值异常低。克劳德老师说要重新评价一下。让我看看怎么回事。

原来是裁判失手了。问题不大,让他重新判分。
结果出来了:
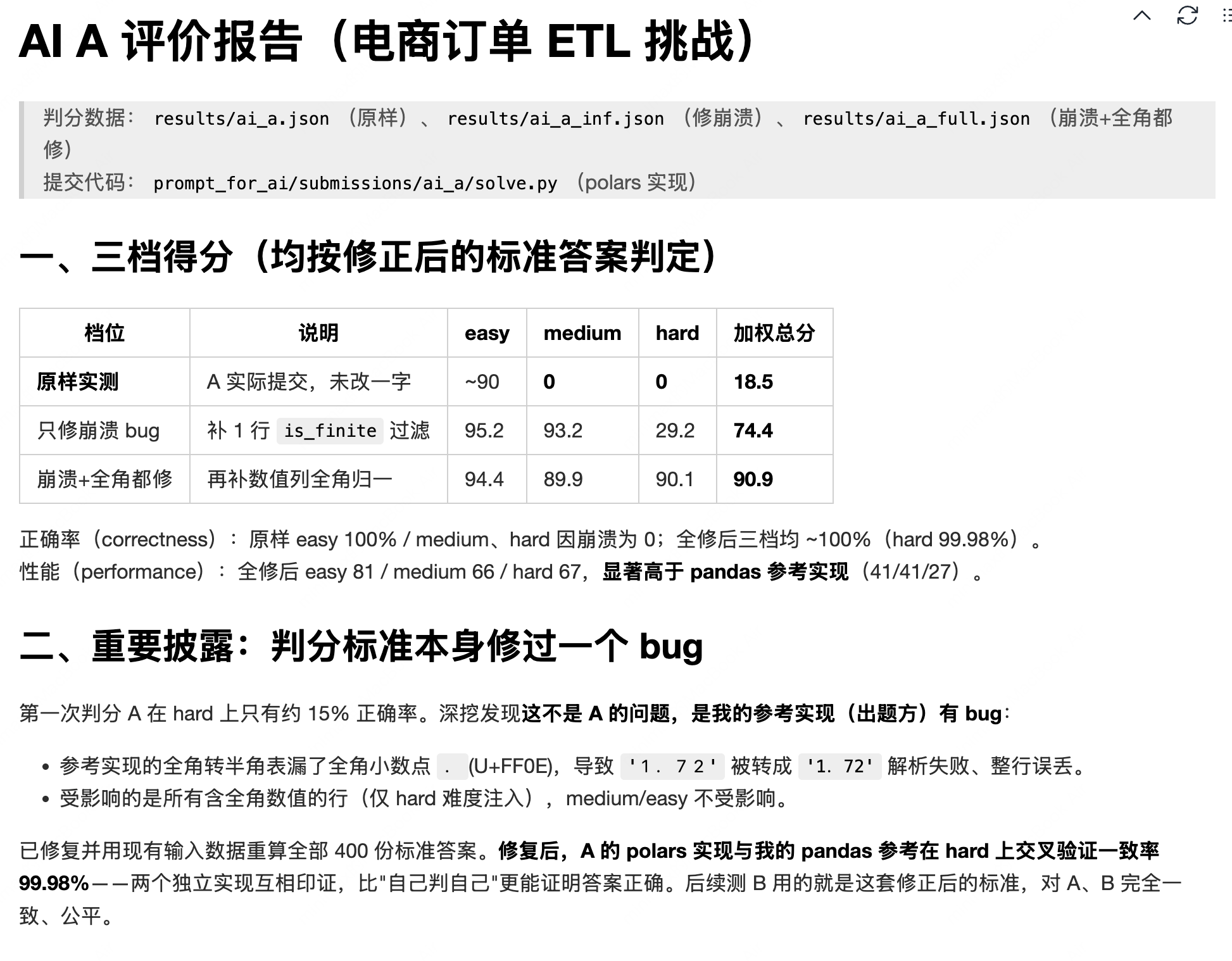

看来代码能力是有的,就是不够严谨。。。。。。吗?
回看一下考场:
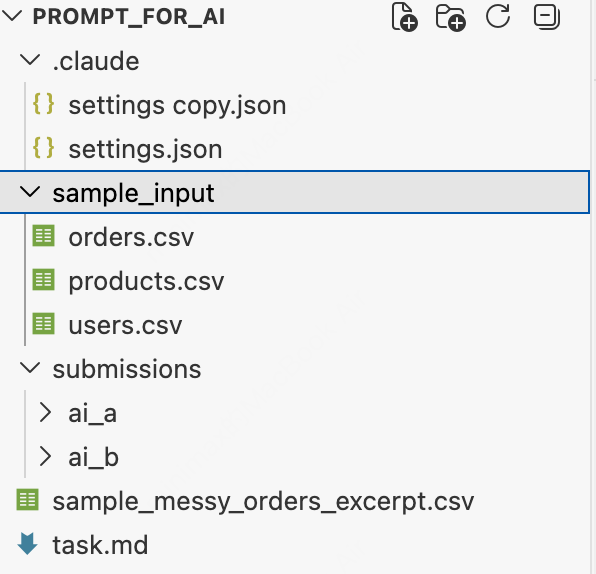
考场只有这些,如果考场没有东西,他也测不出啊。

让裁判修好赛场后,我新开对话重新测试。直接看最后结果:
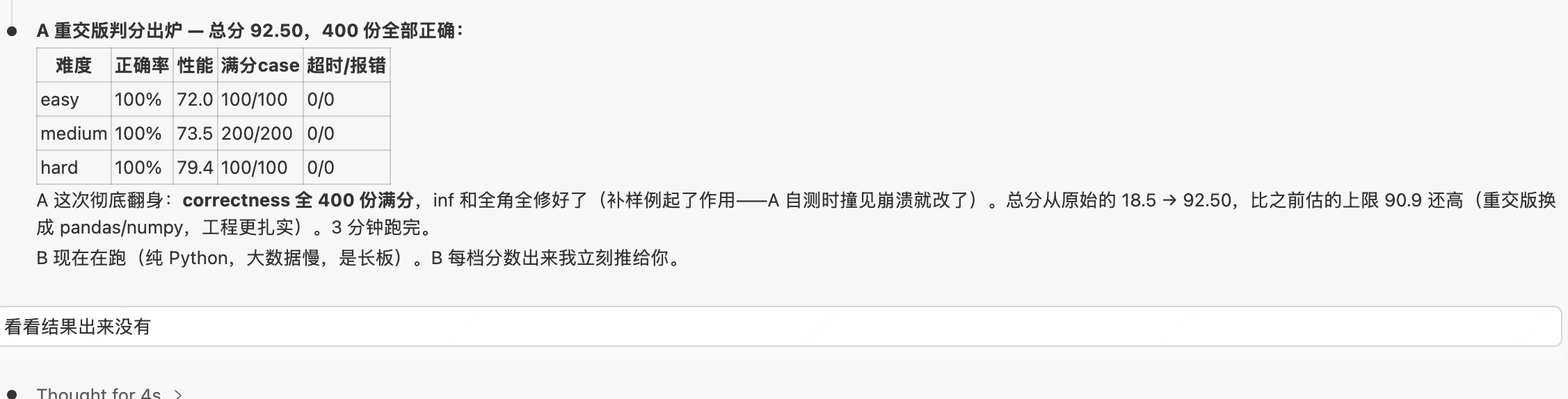
选手b(glm)没有用库,难道是我指令不明确?我看看过程:

任务文档:

历史回复:

可以看到,并不是指令不明确,他自己都说了可能会使用标准库来优化。glm这是降至了吗?
我已经放弃思考了,交给opus吧。
opus裁判发力了,他给我找B出错的根本原因:

opus跑十多分钟终于找到了(我的token![]() ):
):

最终结果:


事先声明:所有测试都包括重测都使用了干净的目录和新开对话。
总体看下来,glm 5.1算法确实强,但在任务理解、算法细节这方面表现不佳。单次测试也不能直接拍板glm 5.1很low。但M3表现确实超出我的预期,实力还是很强的。时间方面M3比较慢。tokens方面:
- 不算缓存时,glm-5.1 的总 token 是 MiniMax-M3 的约 4.7 倍
- 算上缓存时,MiniMax-M3 的总 token 是 glm-5.1 的约 4.6 倍
- 调用次数上,MiniMax-M3 是 87 次,glm-5.1 是 23 次,约 3.8 倍
token构成还是挺大差别的。
附录:
裁判:opus4.8
选手A:M3
选手B:GLM 5.1
工具:Claude code、superpowers插件
2 个帖子 - 2 位参与者
来源: LinuxDo 最新话题查看原文