- 我的帖子已经打上 开源推广 标签: 是
- 我的开源项目完整开源,无未开源部分: 是
- 我的开源项目已链接认可 LINUX DO 社区: 是
- 我帖子内的项目介绍,AI生成、润色内容部分已截图发出: 是
- 以上选择我承诺是永久有效的,接受社区和佬友监督: 是
以下为项目介绍正文内容,AI生成、润色内容已使用截图方式发出
最近在linux.do社区开源的项目,得到佬友的支持和喜爱:
电商爆款复刻AI:
本帖使用社区开源推广,符合推广要求。我申明并遵循社区要求的以下内容: 我的帖子已经打上 开源推广 标签: 是 我的开源项目完整开源,无未开源部分: 是 我的开源项目已链接认可 LINUX DO 社区: 是 我帖子内的项目介绍,AI生成、润色内容部分已截图发出: 是 以上选择我承诺是永久有效的,接受社区和佬友监督: 是 以下为项目介绍正文内容,AI生成、润色内容已使用截图方式发出 电商 AI…
拼豆AI:
github.com
GitHub - liangdabiao/perler-beads-ai: 因为市面上的拼豆软件差强人意 ,所以我基于开源项目:Zippland/perler-beads...
因为市面上的拼豆软件差强人意 ,所以我基于开源项目:Zippland/perler-beads ,带小程序(perlerBeadsApplet) 我加上AI优化了项目,AI辅助优化图片功能,写了一个专门生成拼豆图纸的网站。 经过大量测试,我觉得已经可以达到 一键生成拼豆图纸了!我还有乐高积木拼豆: github.com/liangdabiao/brickMosaic
开源非常有用的项目:多模态RAG
github.com
GitHub - liangdabiao/Multimodal-RAG: 基于多模态 Embedding + Zilliz + Qwen 视觉理解的多模态 RAG 系统。支持...
基于多模态 Embedding + Zilliz + Qwen 视觉理解的多模态 RAG 系统。支持 **Cohere / DashScope Embedding** 和 **DashScope / OpenRouter LLM** 双引擎切换。上传 PDF,用自然语言提问,系统自动检索最相关的页面并由 AI 生成回答。 与传统 RAG 不同,本系统**不做文本提取和 OCR**,而是直接将 PDF 页面当作图片处理,通过视觉 Embedding 模型编码,完整保留表格、图表、排版、手写批注等所有视觉信息。
基于多模态 Embedding + Zilliz + Qwen 视觉理解的多模态 RAG 系统。
1,这次我刻意打造2个大模型方案,1个是国内版本,1个是国际版本。国内版本就直接取用阿里云百炼的API, 而国际版本就是取用了openrouter+cohere的API。 .env里面配置切换就可以。 支持 Cohere / DashScope Embedding 和 DashScope / OpenRouter LLM 双引擎切换。,
2,核心功能:上传 PDF (我这个不需要解析PDF,直接类似人一样整页阅读理解图文),用自然语言提问,系统自动检索最相关的页面并由 AI 生成回答。 与传统 RAG 不同,本系统不做文本提取和 OCR,而是直接将 PDF 页面当作图片处理,通过视觉 Embedding 模型编码,完整保留表格、图表、排版、手写批注等所有视觉信息。
3,回答问题的时候,AI也会找到相关的多页,整理好答案,图文具体的回答。我自己测试很多了,效果太好了。反正我过去那些rag方案达不到这个真正理解pdf图片的效果。所以我推荐我项目给佬试试。
4,
工作原理和流程(AI辅助设计)
PDF 文档
│
▼ (PyMuPDF, 150 DPI)
页面图片(不做任何文本提取)
│
▼ (Embedding API, 云端调用)
│ ├─ Cohere embed-v4.0 → 1 个 1024 维向量
│ └─ DashScope tongyi-embedding-vision-plus → 1 个 1152 维向量
每页图片 → 1 个向量
│
▼ (写入 Zilliz Serverless 云向量数据库)
doc_name + page_idx + vector
│
══════════════ 用户提问时 ══════════════
│
▼ (Embedding API 编码查询文本)
查询 → 1 个向量
│
▼ (Zilliz 内积相似度搜索)
Top-K 最相关页面
│
▼ (页面原始图片 + 问题 → 视觉大模型生成回答)
│ ├─ DashScope: qwen3.5-flash / qwen3.5-plus / qwen3-vl-plus(国内推荐)
│ └─ OpenRouter: qwen/qwen3.5-397b-a17b(海外可用)
AI 直接"看图"回答问题
实际演示:
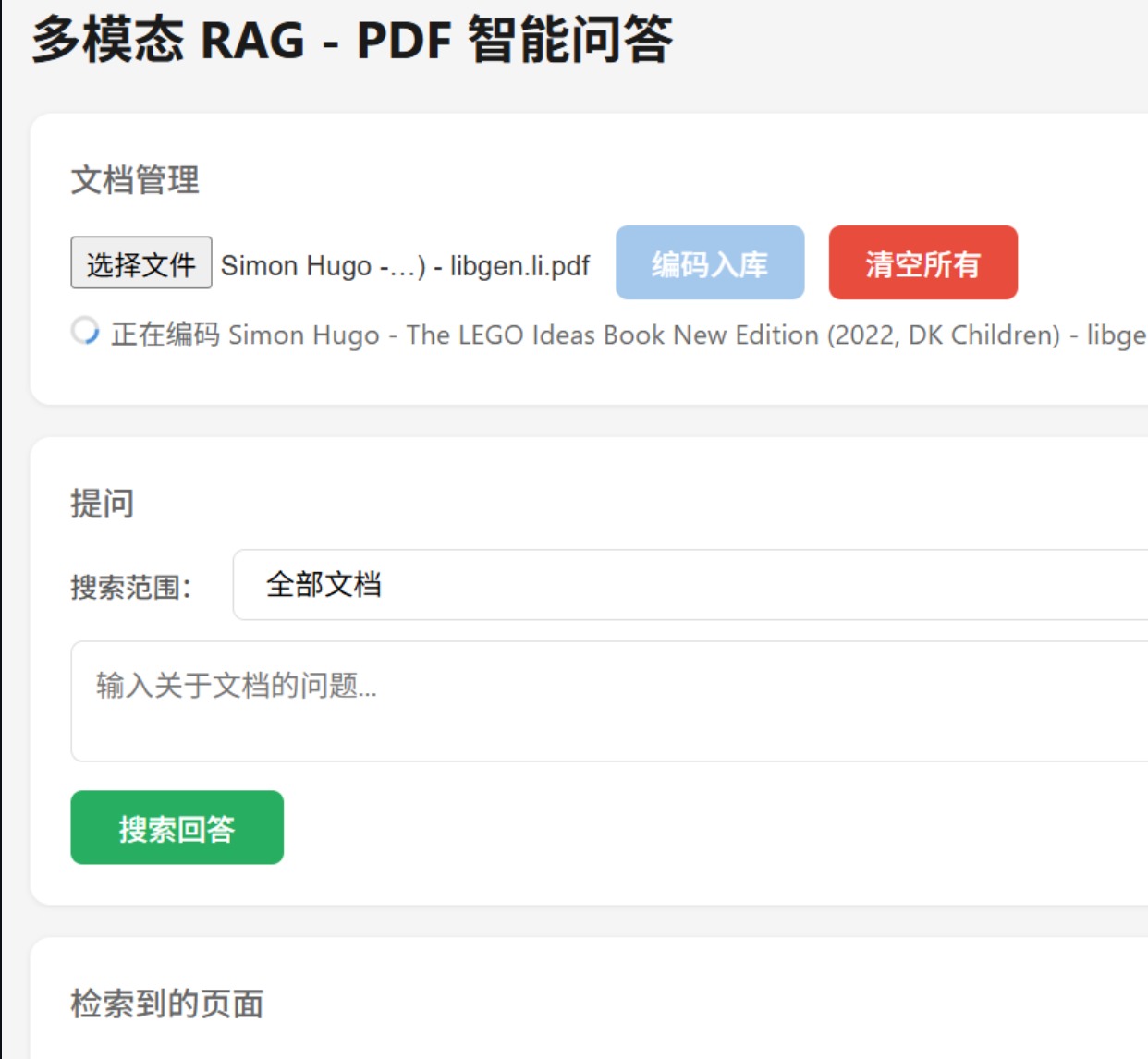
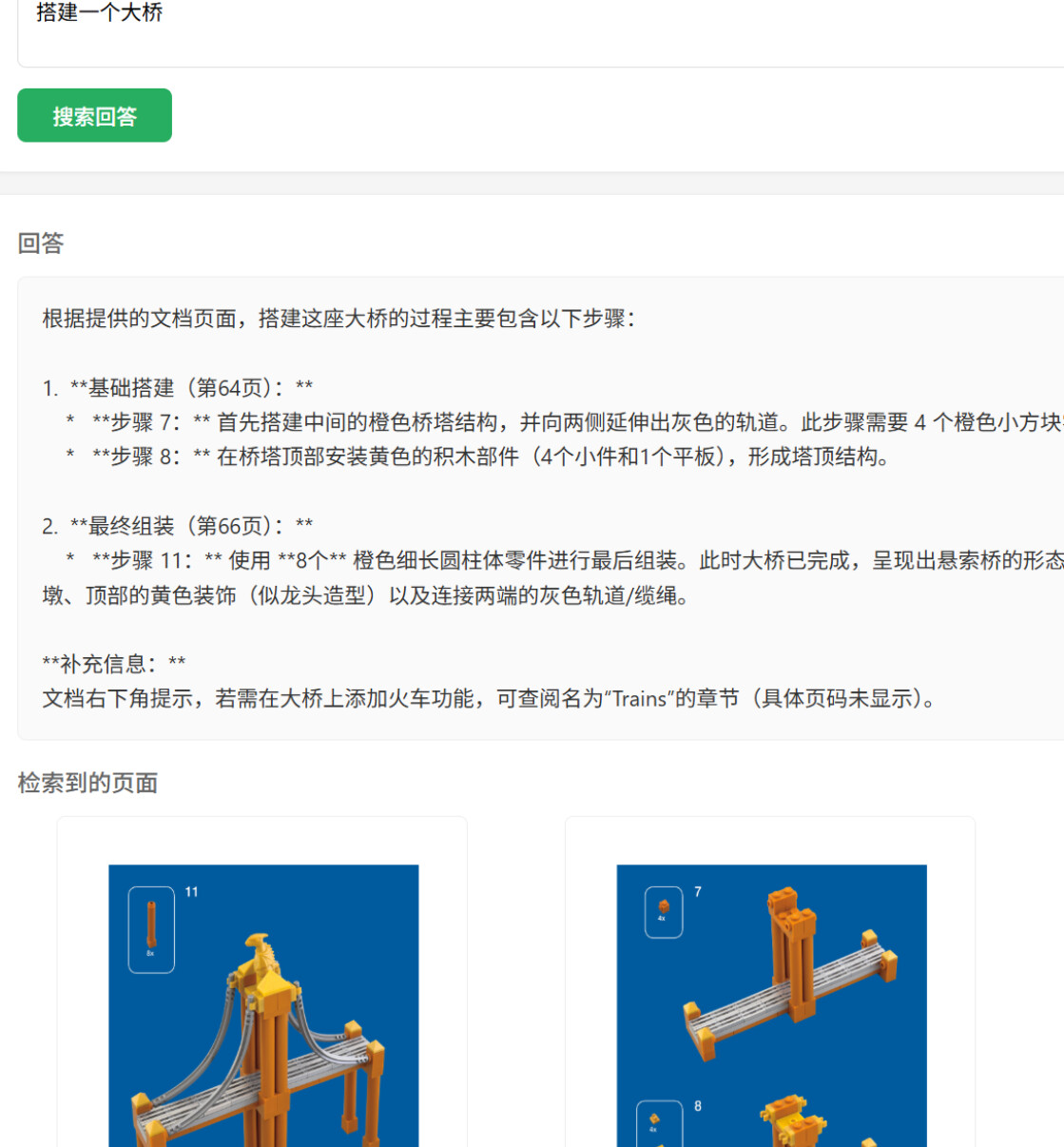
开源地址:
github.com
GitHub - liangdabiao/Multimodal-RAG: 基于多模态 Embedding + Zilliz + Qwen 视觉理解的多模态 RAG 系统。支持...
基于多模态 Embedding + Zilliz + Qwen 视觉理解的多模态 RAG 系统。支持 **Cohere / DashScope Embedding** 和 **DashScope / OpenRouter LLM** 双引擎切换。上传 PDF,用自然语言提问,系统自动检索最相关的页面并由 AI 生成回答。 与传统 RAG 不同,本系统**不做文本提取和 OCR**,而是直接将 PDF 页面当作图片处理,通过视觉 Embedding 模型编码,完整保留表格、图表、排版、手写批注等所有视觉信息。
我觉得这个项目适合那些很难解析成文字的图文内容,零件图, 流程图, 漫画,图文丰富和复杂的,更多是视觉理解而不是文字理解的那些RAG需求,我也是搞乐高拼搭图所以搞这个项目,效果比以前的解析pdf好很多。感谢佬友支持。
4 个帖子 - 3 位参与者