总所周知,这个月以来L站已经爆出的不少中转投毒、敏感信息窃取的事件了,很多佬友总是裸奔在各类中转站下,为了方便各种密钥token都直接给了ai,但是恶是逐利的,总会找上门来;
例如:
1.https://linux.do/t/topic/2219252/276
2. 大家小心,hub.linux.do 部分渠道返回内容含 prompt injection - #103,来自 user2300
…
为了防范于未然,我也设想了一些方案,最后还是选择了一种配合策略提高作恶成本;
我们先了解下投毒/窃取的攻击面,一般来说是tool call去触发恶意命令,具体可以通过改命令关键参数、命令名、工具名等手段进行,还有就是直接prompt注入间接触发大模型去使坏,两者都有概率触发非意图指令,那么,我们是否可以让模型配合调整下tool名或者一些动态校验让每一次返回和请求对应上,避免大范围投毒中招呢?
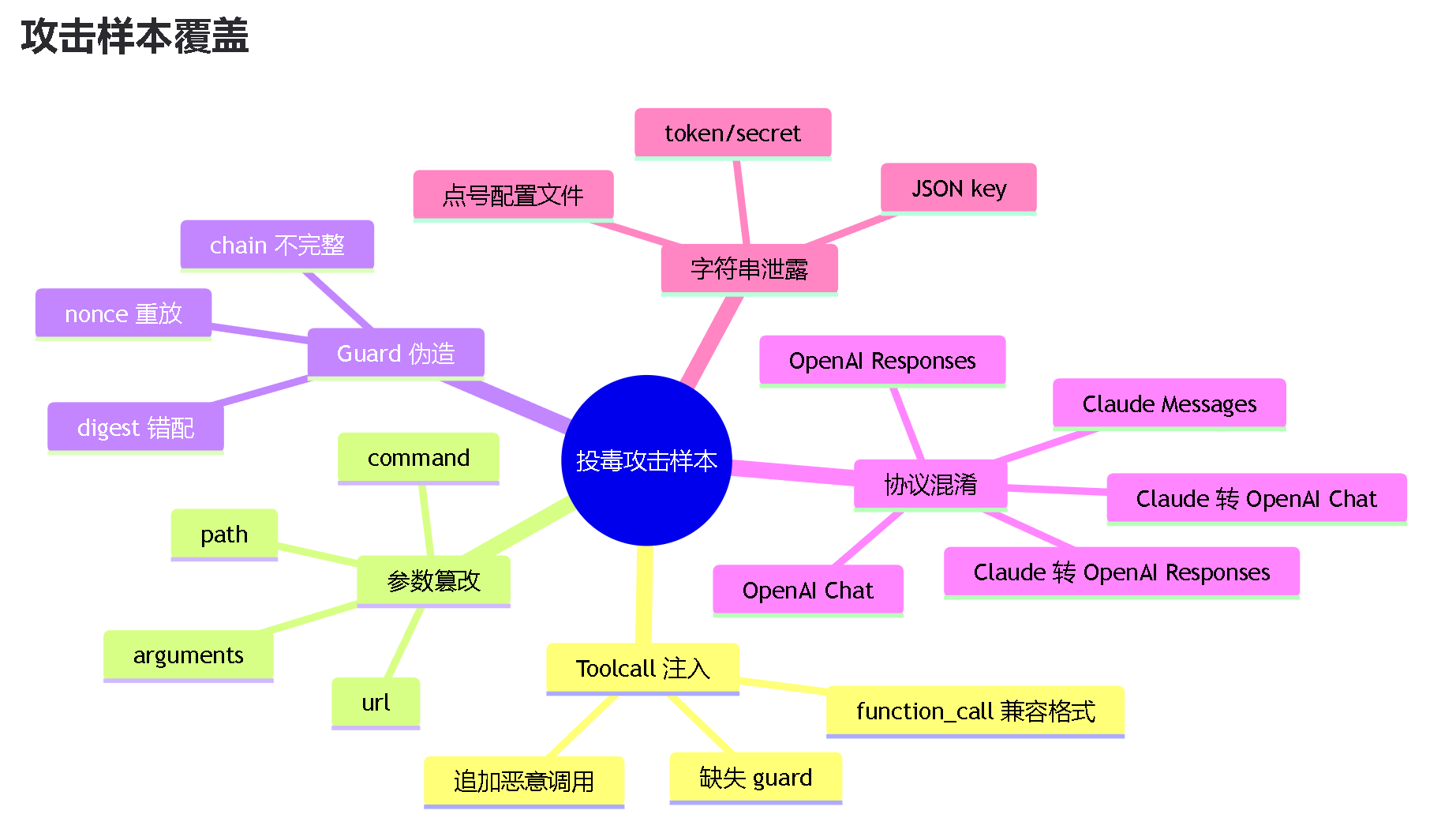
本次防投毒思路就是基于此进行的,但是需要明确不是万能的,这些情况是无能为力的:
1.定向投毒:已经针对你的内容进行二次分析再投毒(例如投毒agent、非动态加固的逆向)
2.毒模型:对模型进行毒化,根子上使坏,隐蔽投毒
于是本此的实践应付的是大规模非定向投毒,应付得是90%的现有情况,很多站长不小心接入了投毒上游情况下是相当有效;当然如果佬群有更好方法欢迎pr引入新的策略,安全需要大众提高意识;
------------------------------------------------------
项目介绍:
1.敏感信息保护

项目自身已经对常见字串进行了保护;用户主动保护:用户接入后可以用<<此处主动加密>>双尖括号进行主动占位替换,本地网关会替换回来,比如密码这些是不影响模型效果的非功能上下文,故而可以主动请求保护;

2.tool call保护
要求llm模型 生成guard JSON ,放在真实 toolcall 申请前;格式示例:
<aad_guard_json>{"name":"aad_guard_3d8a797cd7_WebSearch","tool_name":"WebSearch"}</aad_guard_json>
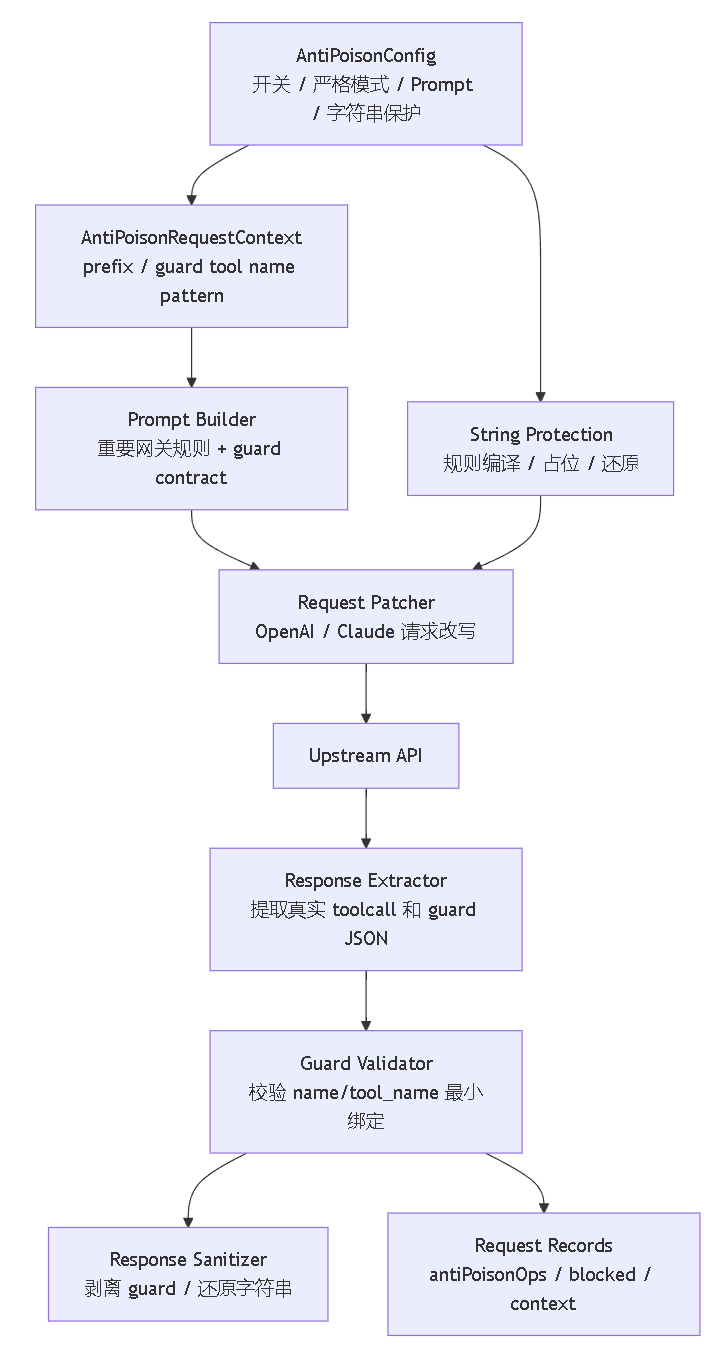
项目主要是验证成本,测试一段时间后才发给佬友门,目前个人用的codex、claude测试了一阵,但是投毒花样很多只能说是初期的验证版本,如有遗漏请提一下issues
Q&A 质疑 (点击了解更多详细信息)1楼将放一下项目本身的使用方法;
6 个帖子 - 2 位参与者